CLIP 논문은 먼저 논문을 읽기위해 파일을 열어보는 순간 길이에 대해 압도당한다. 거의 50쪽에 가까운 논문양에 미뤄두다가 며칠에 걸쳐 조금씩 읽었다. 이해가 잘 되지 않는 부분은 ChatGPT의 도움을 받았다. 챗지 선생님의 과외를 통해 공부 생산성이 20배는 향상된 느낌이다.
지금껏 내가 봐온 논문의 개수가 매우 제한적이지만 그 중 가장 많은 정도의 실험을 통해 본인들의 논리를 탄탄하게 쌓아갔다는 점에서 감탄하며 논문을 읽었다. 저런 규모의 연구를 한다면, 연구를 미리 계획을 할때 무슨 무슨 실험을 해야겠다는 점을 어떻게 계획할까? 공동 연구에 대한 경험이 적은데, 이 실험을 하면서 어느 시점에 공동 연구진의 도움을 추가로 받는 것인지 궁금하다.
연구진은 웹 상에 있는 자연어와 이미지 쌍을 같은 공간에 학습하는 멀티 모달(multi modal) 방식을 통해 테스크에 구애 받지 않고 파인튜닝 없이 제로샷(zero-shot)으로 다양한 테스크에 전이 가능한 모델을 학습하였다.
모델의 구조는 아래와 같다.
웹에서 구한 이미지와 텍스트 쌍(pair)를 한번에 학습하는데, dot product를 통해 같은 이미지 텍스트 쌍은 더 높은 값으로 학습되고 다른 쌍은 학습이 잘 되지 않는 contrasitive 한 방식으로 모델을 학습시킨다.
테스트 시에도 dot product를 활용해 zero-shot 예측을 하는데, 단순한 클래스의 레이블을 활용하는 것이 아닌 A photo of a {class}의 형태로 웹에서 이미지를 설명하는 듯한 프롬프트를 사용하여 성능을 고도화하였다.
CLIP 모델을 학습시킬때 이미지에 대응되는 텍스트가 코끼리, 개와 같은 label이 아니라 더 자연어스러운(natural language) 텍스트이기 때문이다.
CLIP 모델은 zero-shot 성능이 매우 효율적이다. 그림 2를 보면, 이미지넷분류에서 언어 모델의 주류를 차지하고 있는 Transformer는 자연어처리 초창기 모델인 BoW 방식에 비해 3배나 비효율적이고 BoW는 CLIP보다 4배 비효율적이다.

그림 1에서 설명한 것 처럼 프롬프트 엔지니어링과 여러 프롬프트를 조합하는 앙상블 방식에 대한 실험도 36개 데이터셋에서 진행했다. 이미지 인코더를 resnet 모델들에 대해 실험했는데, 개산량 관점에서 4배의 이득을, 평균 정확도 측면에서 5점의 개선이 있었다.

저자들은 27개의 데이터셋에서 CLIP 모델과 resnet에 linear probe를 더한 지도학습 모델을 비교해 어떤 종류의 데이터에서 더 효과적인지를 밝혀냈다. CLIP 모델은 다양한 태스크에서 성능이 좋아 위성사진이나 미세한 차이, 전문적인 특징 등에 강점이 있는 resnet보다 일반적인 성능이 좋았다고 한다.

제로샷 클립 모델의 경우 resnet, simclr 같은 모델들보다 성능이 좋다. 그런데 재미잇는 점은 클래스별 4장의 추가학습을 한 Linear probe(CLIP의 모델 위에 선형 Layer 추가) 방법과 성능이 비슷한 수준인데, 그 이하의 학습을 한 모델은 제로샷보다 성능이 떨어진것이다. 이미 제로샷 모델로 풍부한 표현력을 학습하여 추가적인 4샷의 학습으로는 오히려 표현력이 약해진 것이다.

그림7의 결과로는 데이터셋 별로 CLIP의 제로샷 성능과 같은 성능을 내려면 얼마나 많은 샷을 학습시켜야 하는지가 나타난다. 평균적으로 20개의 샷이 필요하지만 편차가 매우 큰 편으로 그림 6의 실험과 같이 CLIP 모델은 일반적인, 대중적인 표현에 강점이 있음을 알 수 있다.

그림 8에서 CLIP 모델(y축)은 CLIP 모델에 선형 분류기를 추가(x축)한 것과 비교하였는데, 아무래도 제로샷 모델이 선형분류기를 추가한 것보다 y=x보다 아래로 성능이 낮긴하다. 그럼에도 0.82의 양의 상관관계가 있음을 알 수 있다.

모델의 크기가 커져 연산량이 많아질수록 에러율이 낮아지는 것도 알 수 있다.

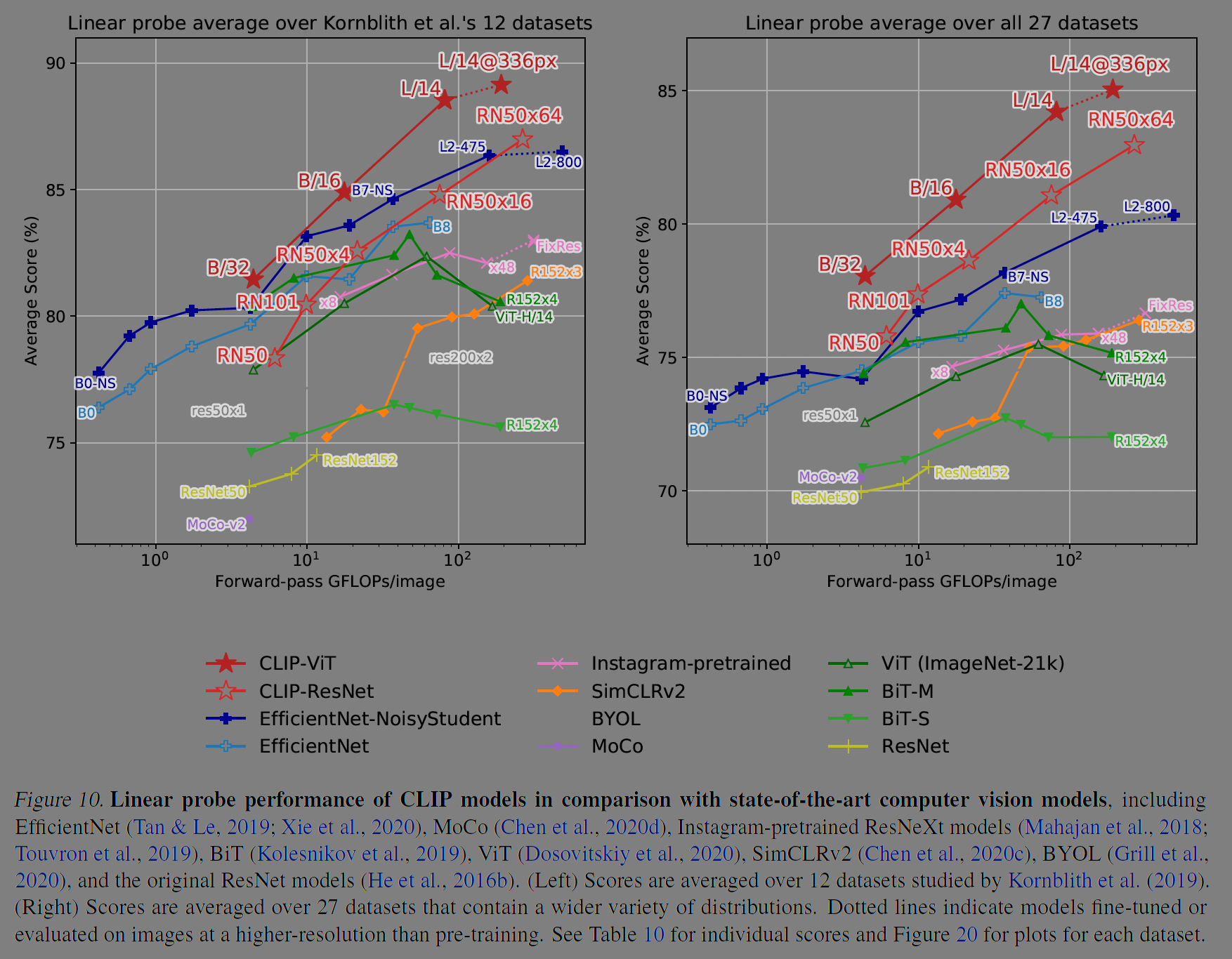
Linear probe에 대해 이미지를 처리하는 연산량과 여러 데이터셋(12개, 27개) 데이터셋의 평균 점수를 보면, 연산량 당 효율이 Base model, Large 모델등 CLIP모델이 우위에 있다.
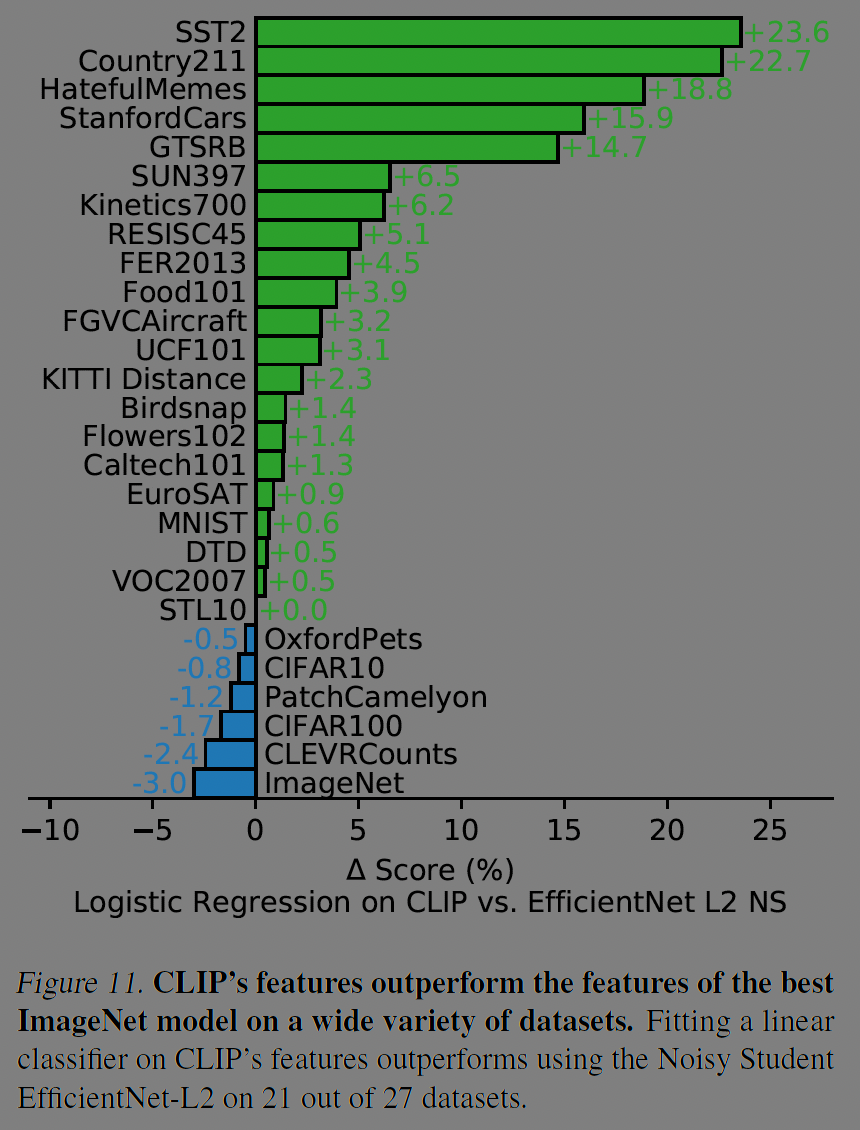
27개 데이터셋 중 대부분의 데이터셋(21개)에서 CLIP이 resnet을 outperform한다.
이미지넷 기반의 모델은 태스크가 달라지면(task shift) 성능이 많이 하락하곤 했다. 이미지넷 모델 경우 이미지 분류 태스크에 대해 과적합(overfit)되었다고 할 수 있다. CLIP모델을 바탕으로 학습한 전이(transfer)의 성능도 좋다. 다른 데이터셋이나 태스크에 강건하다(robust).

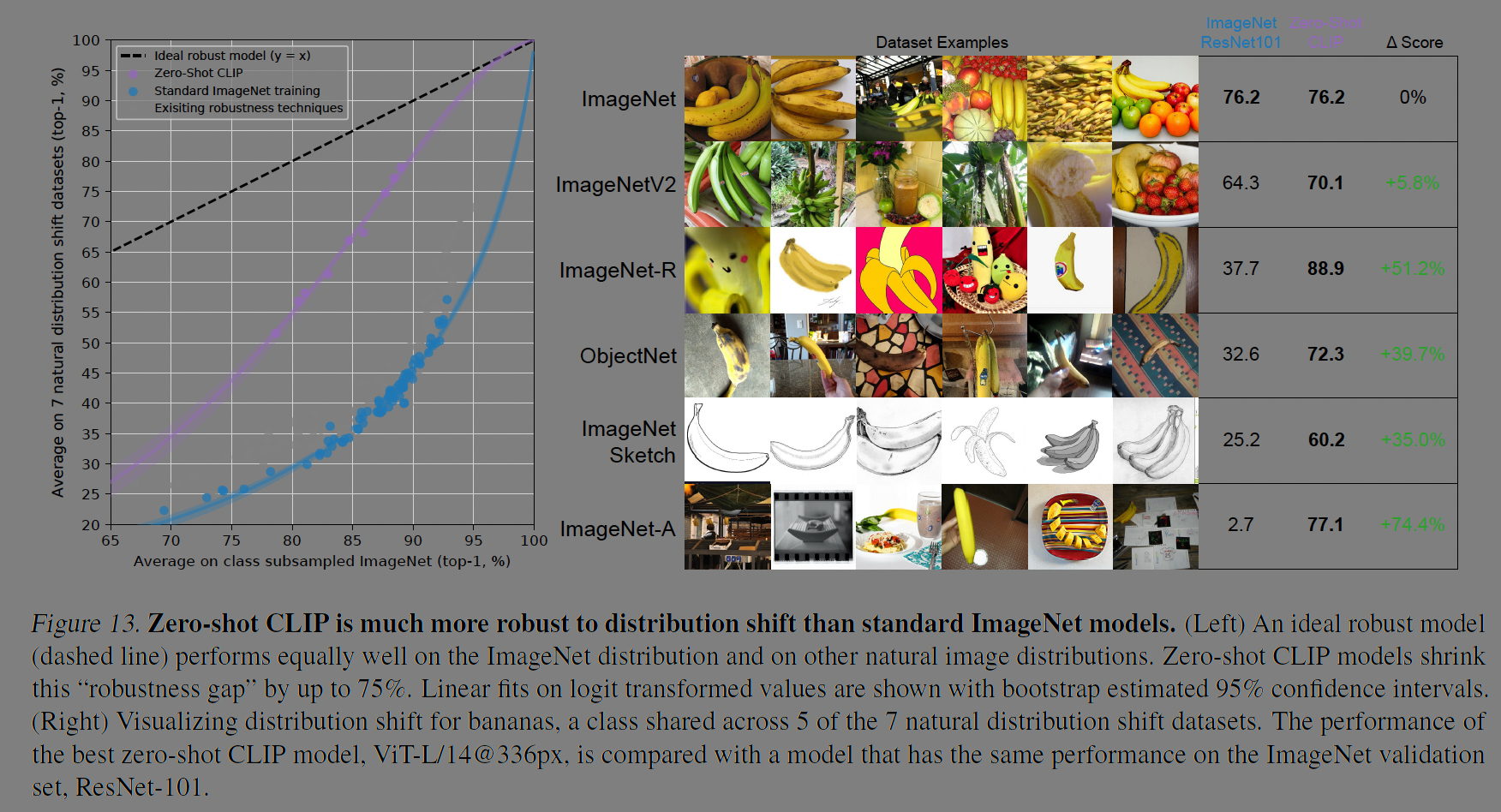
데이터 분포 변화(distribution shift)에도 강건하다. 이미지넷을 확장한 V2, -R이나, 객체탐지, 스케치등의 태스크에서도 resnet101보다 훨씬 나은 성능을 보이는데, 그림 13을 보면 바나나라는 표현을 잘 학습한 것을 알 수 있다. 왼쪽 그림에서는 분포의 변화가 있을때, 이미지넷 모델에 강건성을 확보하기 위한 기법을 적용했을때보다 제로샷 CLIP 모델이 훨씬 나은 성능을 보인다.
이미지넷 성능과 자연스러운 분포 변화의 평균을 사이에서 일반적인 이미지넷 학습 모델은 성능이 매우 떨어진다(좌측 파란색). 제로샷 클립은 분포 변화에 강건하고 adapt to ImageNet을 하는 경우 이미지넷의 성능은 많이 증가하지만 다양한 태스크에서는 성능이 감소한다(우측 상단 그래프). 클래스 변경(class shift)의 경우 이미지넷 기반은 강화되고 손실은 없다.

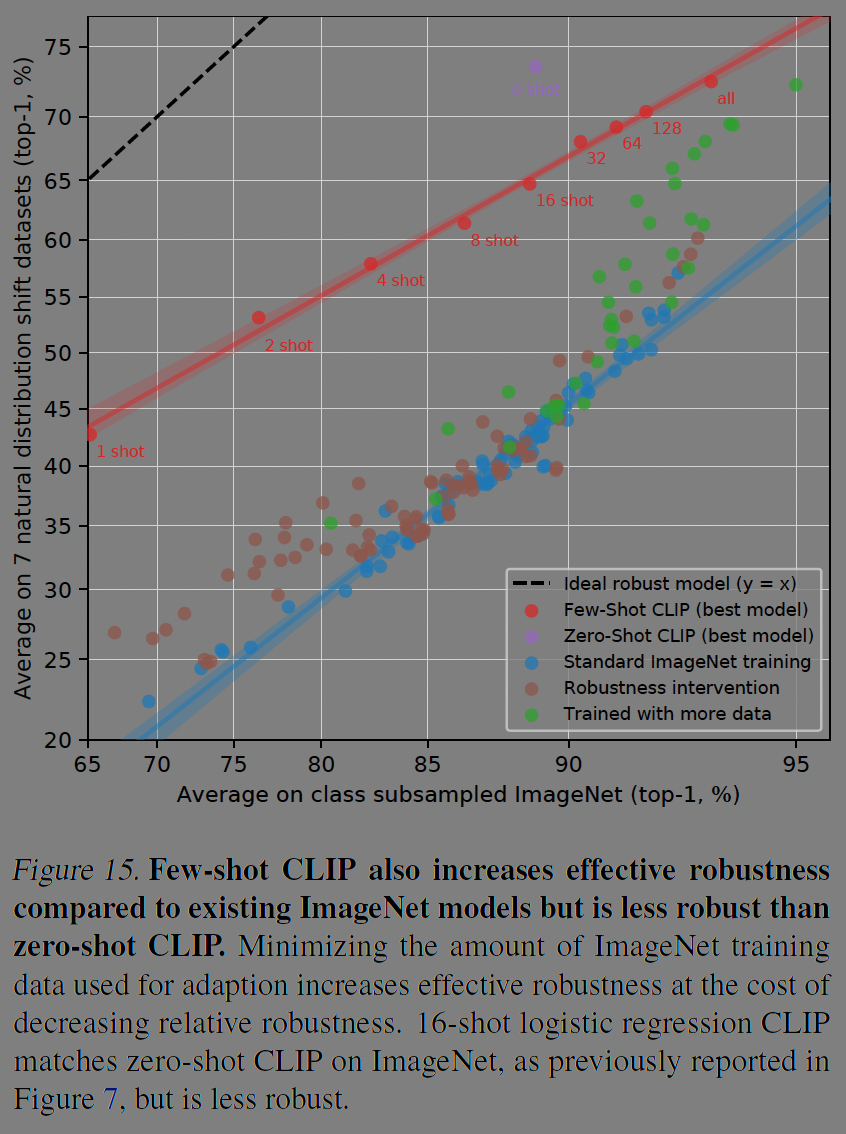
제로샷 CLIP 모델과 few-shot CLIP모델의 비교도 있다. few-shot의 경우에도 이미지넷보다는 강건하지만 제로샷보다는 비효율적이다.
CLIP이 잘 못하는 것은 사람에게도 어려운 일이다. 사람의 경우 원 샷 러닝에 강점이 있다. 아예 못본 이미지를 한번이라도 보는 순간, 그에 대한 인식을 잘 하는 것이다. 반면 여러번 봐도 첫번째 본것 만큼의 인식 강화는 없다(표 2).


아래 실험은, 데이터 중복과 성능에 대한 상관관계를 연구한 것인데, CLIP모델은 웹에서 매우 많은 수의 데이터를 수집해 학습에 사용하였기 때문에 데이터 중복이 필연적으로 발생한다. 성능에는 일부 중복이 있어도 크게 영향을 미치지 않는다.

이처럼 그림이 자그마치 17개 이상이고 Appendix를 포함하면 수십장이 더있다. 이런 규모의 실험을 할 수 있는 인프라와 실험 설계역량이 대단하다고 느껴진다.


