이번 블로그에서는 Zero-Shot Learning Through Cross-Modal Transfer 논문의 마지막 부분을 정리한다.
Zero-Shot Learning Model
이미지 x가 주어졌을때 클래스(seen, unseen) y를 조건부확률로 예측한다. 일반적인 분류기는 학습하지 않은 클래스를 예측할 수 없기에 저자는 binary visibility random variable을 도입한다.

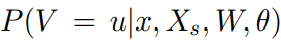
식은 이미지가 unseen 클래스일 확률이다. 이상치 탐지 점수의 경계(threshold of outlier detection score)에 의해 계산된다. 이 점수는 단어 공간에 매핑된 학습이미지의 매니폴드 상에서 계산되는데, Gaussian mixture 상의 경계에 있는 한계 값을 사용한다.
Seen 클래스의 매핑된 포인트들은 아래 수식으로 획득한다. 각 클래스의 가우시안은 연계된 모든 포인트에서 측정된 평균과 공분산 행렬에 의해 파라미터화 된다. 학습가능한 모든 포인트에 의해 클래스의 확률분포를 학습한다는 뜻 같다. Overfitting 을 방지하기 위해 가우시안이 isometric 하도록 했다.
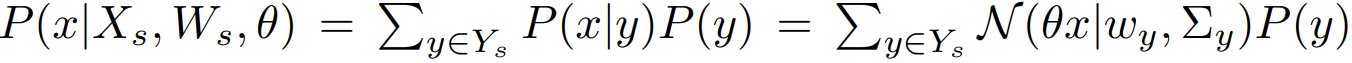
새로운 이미지가 있으면 아래 그림의 threshold에 의해 이상치 탐지를 한다.

Seen 클래스는 softmax 분류기를 사용하여 분류한다. zero-shot 클래스는 의미 벡터에 대해 isometric Gaussian distribution을 가정한다. 다른 방법으로는 각 테스트 포인트에 이상치 탐지를 위해 Seen, unseen 클래스를 판별하기 위한 분류기를 가중치를 두어 사용한다.
Experiments
실험에 32 * 32 * 3 RGB 이미지(10개 클래스, 각각 5,000개)를 가진 CIFAR10 데이터 셋을 사용했다. 각 이미지 별로 12,800 차원의 벡터를 추출하기 위해 Coates and Ng이 사용한 비지도 특징 추출을 했다.
Zero-Shot Classes Only
저자는 두개의 zero-shot 클래스를 실험에 사용했다. Seen 클래스가 없으면 모델의 성능이 random에 가까워진다. 즉 unseen 클래스만 학습에 사용되 unseen 클래스들이 서로 가까운 클래스라면 seen 클래스가 subspace로 적절하게 span 하지 않기 때문에 성능이 좋지 않다. 예를 들어 cat과 dog가 학습에서 빠지면 나머지 8개 클래스에서 2클래스의 특징을 파악하기 어렵기 때문에 zero-shot 분류가 잘 되지 않는다. 반대로 Car, truck이 unseen 클래스라면 예측 성능이 높다. 아래 그림에서는 이상치 탐지 임계점(negative log-likelihood)에 따른 정확도 차이를 나타낸다.

Zero-Shot and Seen Classes
위의 그림에서 unseen, seen을 나누는 임계 값에 따라 80% 정도의 정확도가 나오는 것을 알 수 있다. 70% 정확도에서 unseen 클래스는 15~30%의 확률로 구분할 수 있다.
Conclusion
저자는 단어와 이미지 표현에 기반한 zero-shot 분류를 소개한다. 주된 아이디어는 첫째로 비지도 방법으로 학습된 분류별 단어 벡터가 범주별 지식 표현에 도움이 된다는 것이다. 둘째로 이상치를 탐지하는 베이지안 프레임워크가 zero-shot, seen 클래스를 다 분류하는 것이다. 거의 90%의 정확도를 확보하였다.
논문을 읽으며 베이지안 방법을 어떻게 구현하는지 실제 코드 레벨로 공부해야겠다는 생각이 들었다. 전이 학습 역시 코드 실습을 통한 이해가 필요하다. 여러 논문을 통해 실험 걸과를 어떻게 수식으로 도식화한 표와 그래프로 표현하는지도 좋은 공부가 되는 듯하다.


