word2vec으로 유명한 워드 임베딩 모델 CBOW, skip-gram에 대해 발표한 논문이다.
이 논문의 실험은 GPU를 통한 딥러닝 모델학습이 일상화되기 전 시점의 연구로 CPU에서 계산하여 진행하였다. 저자들은 CPU로 대규모 데이터를 학습하고 실험하느라 꽤나 고생 했을 듯하다... 선배 연구자들이 고생한 덕분에 오늘날 더 다양한 연구를 할 수 있는 것이다! 힘을 내자.
Abstract
저자는 대규모 데이터셋에서 단어들을 벡터(continuous vector)로 표현하기 위한 두가지 모델을 제시한다. 단어 유사도 비교 태스크를 통해 모델들의 성능을 비교하고 이전 연구의 신경망 모델과 비교했다. 계산 복잡도에서 이득을 얻으면서도 성능을 개선시켰다. 저자들이 만든 semantic, syntatic 비교 테스트 셋에서도 SOTA를 기록하였다.
Introduction
단어를 원자적(atomic)으로 다루던 때는 단어간에 유사함을 측정하기 어려웠다. 통계적 언어모델 N-gram처럼 큰 규모의 데이터에서 간단한 모델로 학습시킨다면 적은 데이터로 복잡한 모델을 학습시킨 것 보다 강건하다. 이 방법의 성능은 질 높은 데이터를 수집한 규모에 의해 결정되는데 자동 언어 인식 모델, 기계번역 같은 여러 도메인에서는 데이터 수집에 한계가 있다. 저자는 이를 극복하기 위해 scaling up이 아닌 테크닉을 개선하기로 했다.
기계학습이 발전하면서 이전보다 큰 규모의 데이터에서 복잡한 모델을 학습하여 더 나은 성능을 발휘하였다. 가장 성공적인 것으로 단어의 분산 표현(distributed representations of words)의 신경망 기반 언어모델이 N-gram 모델보다 낫다.
Goal of the Paper
이 논문의 주된 목표는 수십억 단어의 데이터 셋(수백만의 학습용 단어사전, vocabulary)에서 고품질의 단어 벡터를 학습하는 것이다. 이 논문 이전에는 수억단위의 50-100 차원의 벡터를 학습한 사례가 없었다.
저자는 유사한 단어가 서로 가까이 모이면서 다양한 정도의 유사도를 표현하는 벡터 표현의 성능을 측정하기 위한 방법을 제시했다. 문맥에 따라 명사 끝이 달라지는 굴절어(inflectional languages)도 가까운 위치에 표현이 가능하다. 단어 표현의 유사성은 문법적인 규칙의 규칙성(syntactic regularities)을 넘어서는 것을 발견하였다. 단어의 대수 표현에서 "king" - "man" + "woman" = "queen"을 벡터로 연산하면 단어 queen과 유사한 단어들을 결과로 얻을 수 있다.
저자는 벡터 대수 연산의 정확도를 최대화하면서 단어들의 선형성을 보장하는 모델을 제시한다. 문법적, 의미적인 규칙을 측정하기위한 테스트셋도 개발하였다. 이 데이터셋에서 진행한 실험을 통해 문법적, 의미적인 규칙을 보존하면서도 고성능을 발휘하는 모델을 개발하였다. 실험의 과정에서 학습 시간과 단어벡터의 차원, 학습에 걸린 시간에 대한 논의를 진행한다.
Previous Work
단어를 연속적인 벡터로 표현하는 것은 꽤나 연구되어온 주제이다. 선형 사영(linear projection)과 비선형 히든층을 포함하는 신경망 언어 모델(Neural Network Language Model, NNLM)이 단어벡터표현과 통계적 언어 모델에 사용되었다. 단일 히든층으로만 학습된 신경망 언어 모델도 있고 본 논문은 이를 확장하였다. 단어 벡터는 자연어처리(NLP) 응용 프로그램에 사용되는데, 다양한 단어 원천으로 학습된 모델에 대한 연구도 있다. 그러나 계산비용이 많이 들기도 하고 이를 줄이기 위한 연구도 있었다.
Model Architectures
모델의 학습복잡도는 아래의 수식을 따른다.
E: epochs
T: 학습 셋의 단어 수
Q: 각 모델 구조의 특성별로 정의되는 수
일반적으로 E = 3 - 50, T = 1bn이고 모든 실험은 stochastic gradient descent, backpropagation을 사용했다.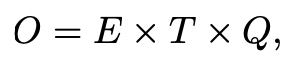
Feedforward Neural Net Language Model(NNLM)
확률적 신경망 언어 모델은 input, projection, hidden, output 층으로 구성되었다.
N: 인코딩 된 이전 단어의 수 (1 of V coding)
V: vocabulary 크기
P: projection 층
N * D: P층 행렬의 크기
N개의 입력만 유효하기 때문에 P층의 계산은 상대적으로 적다. NNLM 구조는 P층과 hidden 층의 계산이 복잡하다. N이 10인경우 P는 500에서 2000에 이르고 H의 크기는 보통 500에서 1000 사이이다. hidden 층은 V차원의 출력층으로 사전에 있는 모든 단어에 대한 확률분포를 계산한다. 학습시에 계산 복잡도는 아래와 같다.
H * V가 가장 주된 계산이다. 이를 줄이기 위한 방법들이 제안되었는데 계층적인 softmax를 사용하거나 학습시에 표준화되지 않은 모델을 사용하여 표준화되는 것을 피한다(오버피팅을 피한다는 것 같음). Vocabulary를 이진트리로 표현해 출력에 필요한 수치를 log_2(V)로 감소시켰고, 주된 계산을 N * D * H로 변경할 수 있었다. 저자는 단어의 빈도가 신경망 모델에서 클래스를 분류하는데 잘 동작하는 허프만 이진트리를 사용했다. 허프만 트리는 빈번한 단어에 짧은 이진 코드를 할당하여 결과를 도출하기위한 과정을 단축시킨다. 균형 이진트리를 사용하는 경우 log_2(V)로 감소시키고 허프만 트리를 사용하는 경우 log_2(unigram_perplexity(V))로 감소시킨다. 백만 단어의 단어장(vocabulary)으로 실험한다면 두배의 시간상 이득을 얻는다. 추후에 N * D * H를 감소시키기 위한 softmax 정규화 방법도 제시한다.
Recurrent Neural Net Language Model (RNNLM)
순환신경망 언어 모델은 문맥의 길이를 명시화해 NNLM 보다 복잡한 패턴을 잘 표현한다. RNN 모델은 projection 층이 없고 hidden 층이 재귀적으로 연결한다. 이는 단기 특징 학습에 강점이 있고 이전 시점의 정보들은 hidden 층에 표현이 된다. RNN 모델의 학습 복잡도는 아래와 같다.
NNLM처럼 V를 계층적 softmax를 이용해 감소시킨다면 학습에 가장 큰 영향을 미치는 요소는 H * H이다.
Parallel Training of Neural Networks
이 연구에서는 여러개의 CPU에서 미니 배치를 사용해 병렬학습을 하고 Adagrad로 learning rate를 적응적으로 감소시킨다.
다음 글에서는 CBOW, skip-gram 모델에 대한 설명과 실험 파라미터에 대한 결과를 비교해보자.



