조경현 교수님이 2014년도에 쓴 논문이다. 당시 주류 번역 방법이던 확률적 기계번역과 신경망 기반의 번역 모델의 성능을 비교하였다.
논문에서 신경망 기계번역이 해결해야할 다음 과제를 제안하고 정성적인 품질이 낮지 않으면서도 문장의 문법적인 구조를 파악할 수 있는 신경망 모델을 제안하였다.
신경망 기계번역(neural machine translation)은 인코더와 디코더로 구성한다. 인코더는 가변길이의 입력을 고정된 길이의 벡터 표현으로 만들고 디코더는 이 벡터에서 가변길이의 번역 타겟을 생성한다. 신경망 기계번역 모델은 통계적 기계 번역(statistical machine translation, SMT)에 비해 상대적으로 메모리가 적게든다(500mb vs 10gb). 그리고 SMT와 다르게 모든 컴포넌트의 성능 개선이 동시에 이뤄진다.
이 연구에서는 RNN 인코더-디코더 모델과 비지도로 문법적인 구조를 학습한 grConv(gated recursive convolutional neural network) 모델을 분석한다. 입력 문장의 길이에 따른 신경망 번역 모델의 성능 저하(BLUE score)와 단어장(vocabulary) 크기가 번역의 양적 품질에 영향을 미치는 것을 제시한다.
RNN은 가변길이 시퀀스의 분포를 학습한다. 매 t 시점에 이전시점의 hidden state와 새로운 입력을 더해 h를 갱신한다(fig 1).
x의 확률은 t시점에 이점 시점 결과의 결합확률로 나타난다. 이 연구에서는 fig 1의 b에 나타난 gru 모델을 사용한다.

저자는 변하는 길이의 시퀀스를 다루기 위한 모델로 gated recursive convolutional neural network(grConv)를 제안한다 (fig 2-a). 같은 층(level)의 파라미터가 공유되면서 모델의 가중치가 재귀적으로 반복하여 하나의 고정된 벡터가 되기 전까지 합쳐지는 이진 convolutional 신경망이다. 일반적인 콘볼루션 구조에 더해 입력 문장의 구조를 즉시 학습하도록 gru의 gating 매커니즘을 더하였다.
특정 층의 각 hidden unit을 계산하는 방법은 논문 원문의 2-3페이지 수식을 참고하자. fig 2-a 의 부분을 뜯어보면 2-b와 같은 gated unit 구조로 되어있다.

머신러닝 관점에서 번역 태스크는 입력 문장이 주어졌을때 출력 문장의 조건부 확률을 학습하는 것으로 볼 수 있다. 조건부확률 모델이 학습되면 분포의 최대치를 찾기위한 알고리즘이나 샘플링을 직접할 수 있다. 연구진은 조건부확률을 극대화하기 위한 beam-search 기법을 적용했다. 디코더의 각 시점에 번역 unknown 단어는 제외한 후보군을 10개(s=10)를 beam-width로 했다.

이 논문에서는 gru 모델과 grConv 모델에 집중해 BLUE 점수로 측정된 인코더-디코더 번역의 연역적인 편향(inductive bias)를 이해하는 것을 목적으로 한다. 실험은 영어-프랑스어를 번역하는 태스크를 평가했다. 데이터셋은 여러개의 데이터셋에 있는 단어들을 합쳐 구축하고 단일언어 셋이 아닌 bilingual한 병렬의 코퍼스를 사용했다. 길이는 30 단어를 최대로 제한하고 두 언어에서 최대 빈번한 30,000개의 단어를 이용했다. 나머지는 unknown 토큰으로 매핑했다. NMT 모델의 성능은 news-test2012, 3(train), 4(test) 데이터로 평가했다. 모델은 RNN Encoder-Decoder (RNNenc), grConv 두 가지이고 두 모델 다 디코더로 gated hidden unit을 RNN과 사용했다.
표1에는 단어 길이 별로 BLUE 시험 점수가 있다 (baseline model: Moses). 성능은 연구가 발표된 시점에는 SMT 모델이 NMT보다 나았고 당시에는 긴 문장에 성능이 좋지 않은 문제가 있었다 . 고정 길이 벡터로 긴 길이의 문장에 대한 정보를 담기 부족했으리라 가설을 두었다. unk 토큰이 없는 경우에 베이스라인과 격차가 줄었다 (table1-b).

저자들은 입출력 문장의 길이와 unk 토큰의 수에 따른 번역 품질에 대해 관심을 가졌다. 우선 번역 성능을 반영하는 BLUE 점수가 입력 길이에 따라 달라지는지 보면 두 모델 다 짧은 문장에서 점수가 높고 길이가 길어질수록 점수가 낮아진다 (fig4). unk 토큰 수에 대해서는 두 모델 모두 음의 양상을 띈다(fig4-c).

기존의 SMT 모델의 성능은 문장의 길이에 영향을 덜 받았다. 그리고 연구의 원문에서 확인할 수 있는 table2에서는 실제 모델들이 번역한 결과를 나타냈다. BLUE 점수는 각각 다르지만 번역의 질적인 품질은 세 모델 다 괜찮은 편이었다.
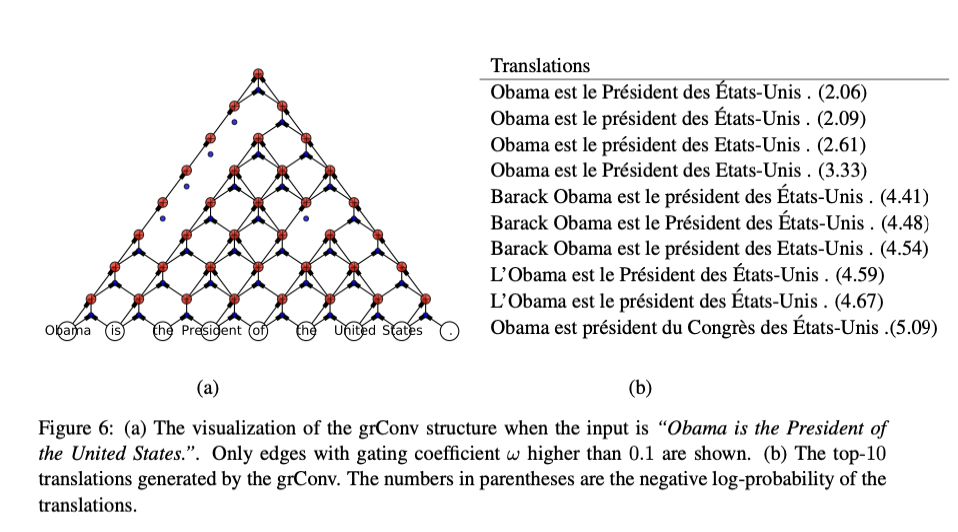
저자들은 gated recursive colvolutional network가 문장의 파싱 구조(parsing structure)를 학습하는지 시각화한다. 'of the United States'와 'is the President of'를 먼저 합치고 후에 'Obama is'를 병합하는 것을 알 수 있다.