이번 글에서는 이 논문에서 제시하는 단어 벡터 표현 방법인 CBOW, Skip-gram에 대해 정리해본다.
New Log-linear Models
저자는 계산복잡도를 최소화하기 위한 단어의 분산표현(distributed representations) 방법을 제시한다. 언어학에서 분산표현은 비슷한 문맥에서 등장하는 단어는 유사한 의미를 갖는다는 것이다. 이전 글을 통해 단어 표현의 가장 큰 계산요소는 비선형(non-linear) 히든 층을 연산하는 것이었다. 히든 층이라는 개념이 딥러닝에서 중요하지만 저자는 더 간단한 모델로 더 많은 양의 데이터를 표현하기 위한 방법을 제안한다.
기존 신경망 모델은 연속적인 단어 벡터를 간단하게 학습한 뒤에 N-gram NNLM을 단어 분산벡터 기반하여 학습한다. 기존 방법은 단어벡터를 학습하는데 너무 많은 자원 소요가 있고 이를 개선하기위해 CBOW, Skip-gram을 제안한다.
Continuous Bag-of-Words Model (CBOW)
처음 제안하는 구조는 순전파 NNLM과 유사하다. 비선형 히든 층을 없애고 사영(projection) 층을 모든 단어들이 공유한다. 단어들의 순서가 사영에 영향을 끼치지 못하도록 같은 위치로 평균을 낸 구조를 a bag-of-words 모델이라고 한다. 이 구조에서는 중심부의 단어 앞뒤 단어들을 사용한다. 이를 통해 가운데 단어를 정상적으로 분류한다. 학습을 위한 복잡도는 다음과 같다.

Standard bag-of-words 모델과 다르게 문맥을 연속적으로 분산하여 표현한다. 입력과 사영층 사이의 가중치 행렬(weight matrix)과 사영층(projection layer)는 모든 단어가 공유한다.
모델의 구조는 아래의 그림에서 skip-gram과 비교하여 표시한다.
CBOW에서는 중심 단어 앞뒤 단어들을 가중치를 통과시킨 후 합치고 다시 가중치를 거쳐 중심 단어에 대한 결과를 출력한다. Skip-gram은 이와 반대의 방식이다.
Continous Skip-gram Model
Skip-gram 모델은 CBOW와 유사한듯 다르다. CBOW가 주변단어로 중심단어를 예측한다면 skip-gram은 문맥의 중심단어로 주변 단어를 예측한다. 한개의 단어를 중심으로 주변단어들이 등장할 확률을 최대화한다. 각 단어를 사영층(continuous projection layer)의 log-linear 분류기에 입력하면 특정 개수의 앞, 뒤 단어를 예측하는 것이다. 저자는 범위를 늘리면 단어 벡터의 질을 높인다는 것을 발견했지만 계산 복잡도 역시 증가한다는 단점이 있다. 더 멀리있는 단어가 중심 단어와 관련이 적기때문에 중심단어에서 먼 단어에 적은 가중치를 중다.
학습 복잡도는 다음 수식과 같다.
C: 단어들의 최대 거리
예를들어 C가 5이면 1~5의 범위에서 임의로 R의 숫자를 고른다.
Results
단어 벡터를 성공적으로 학습하면 단어 벡터들의 대수 연산(algebraic operation)이 가능하다. 그리고 저자의 모델은 단어의 어미가 다른 경우를 구분할 수 있다. 그리고 높은 차원의 단어벡터를 대규모의 단어 셋에서 학습하여 단어들의 미묘한 의미 관계를 이해할 수 있다. 예를들어 France - Paris, Germany - Berlin과 같이 의미를 찾아내는 것이다.
Task Description
단어벡터의 품질을 측정하기 위해 저자는 의미적인(semantic) 문제(8869개)와 문법적인(syntactic) 문제(10675개)를 포함하는 테스트셋을 만들었다. 먼저 유사한 단어쌍의 목록이고 두 단어의 쌍으로 이루어져있다. 예를들어 미국 대도시와 그 도시가 속한 주의 이름 쌍이다. 두 단어 이상이 하나의 의미를 표현하는 경우는 제외하였다. 저자는 의미, 문법 질문에 각각 점수를 측정하였다.
Maximization of Accuracy
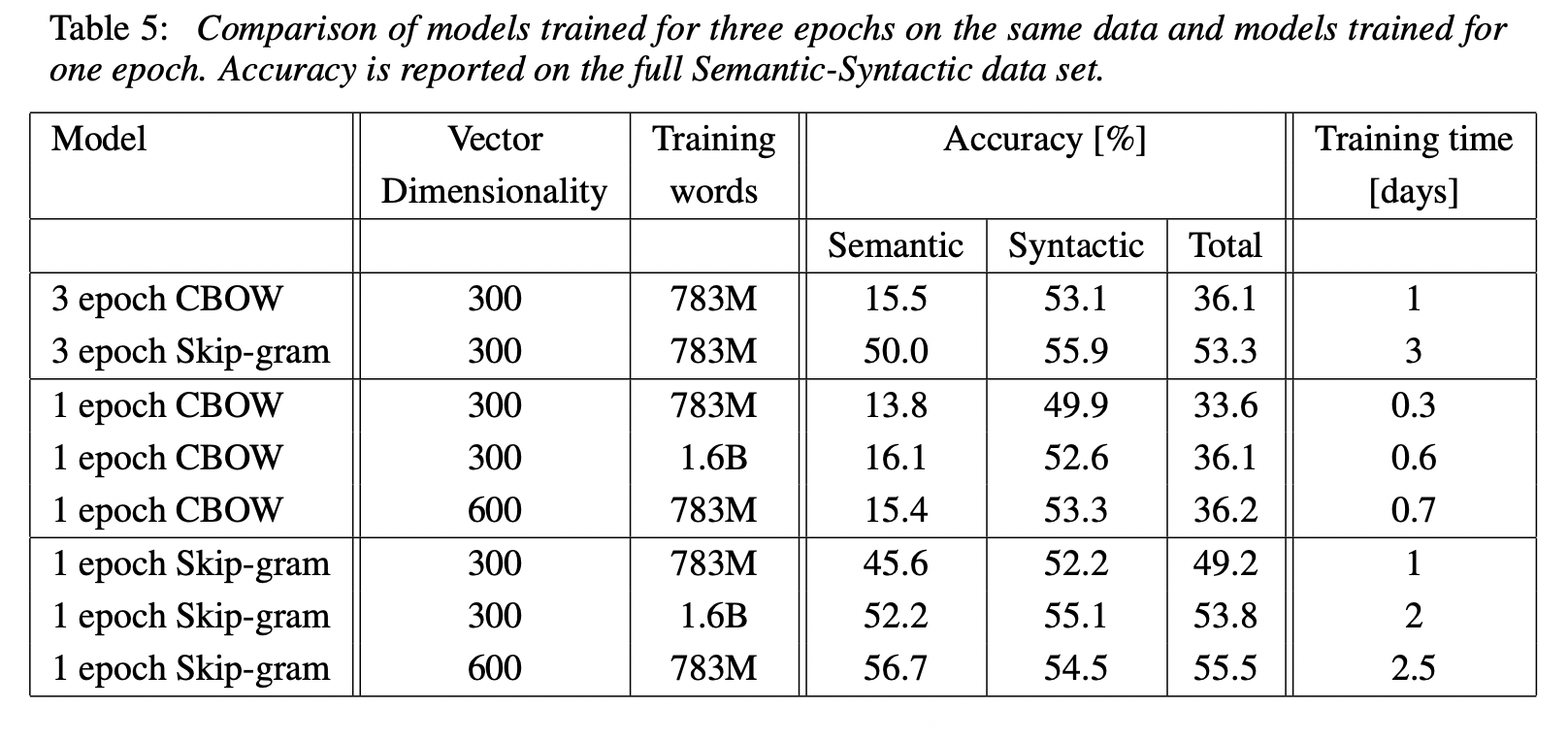
실험에는 6B 토큰을 가진 구글 뉴스 코퍼스가 사용되었다. 이 토큰을 백만개로 줄여 실험하였고 단어 벡터의 크기와 더 많은 데이터가 정확도를 향상시킬 것으로 예상하였다. 이에 대한 실험결과는 아래와 같다. 단어 벡터의 크기와 데이터 양 증가에 대한 개선의 폭이 감소함을 알 수 있다. 위에 언급했던 수식에 의하면 데이터 양이 두배로 늘면 계산 복잡도도 두배로 늘기 때문에 효율이 무조건 개선한다고 보기는 어렵다.
아래 표는 같은 데이터 크기와 차원을 이용하여 모델끼리 성능을 비교한 결과이다.

Comparison of Model Architectures
공개적으로 이용가능한 단어 벡터로 한개의 CPU에서 학습시킨 결과는 다음과 같다.
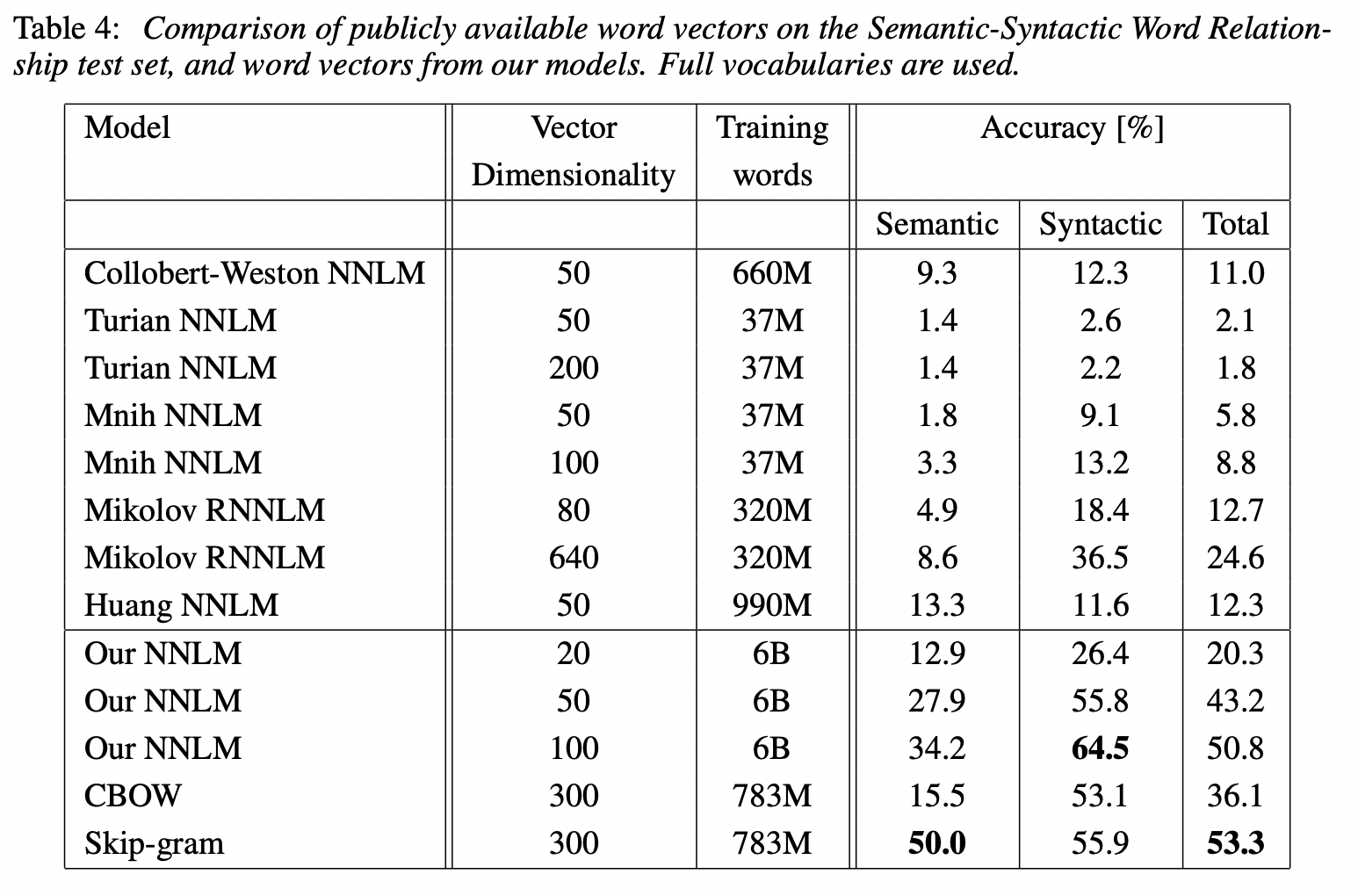
벡터의 크기와 학습 대상 단어의 크기를 각각 두배로하여 실험한 결과는 다음과 같다.
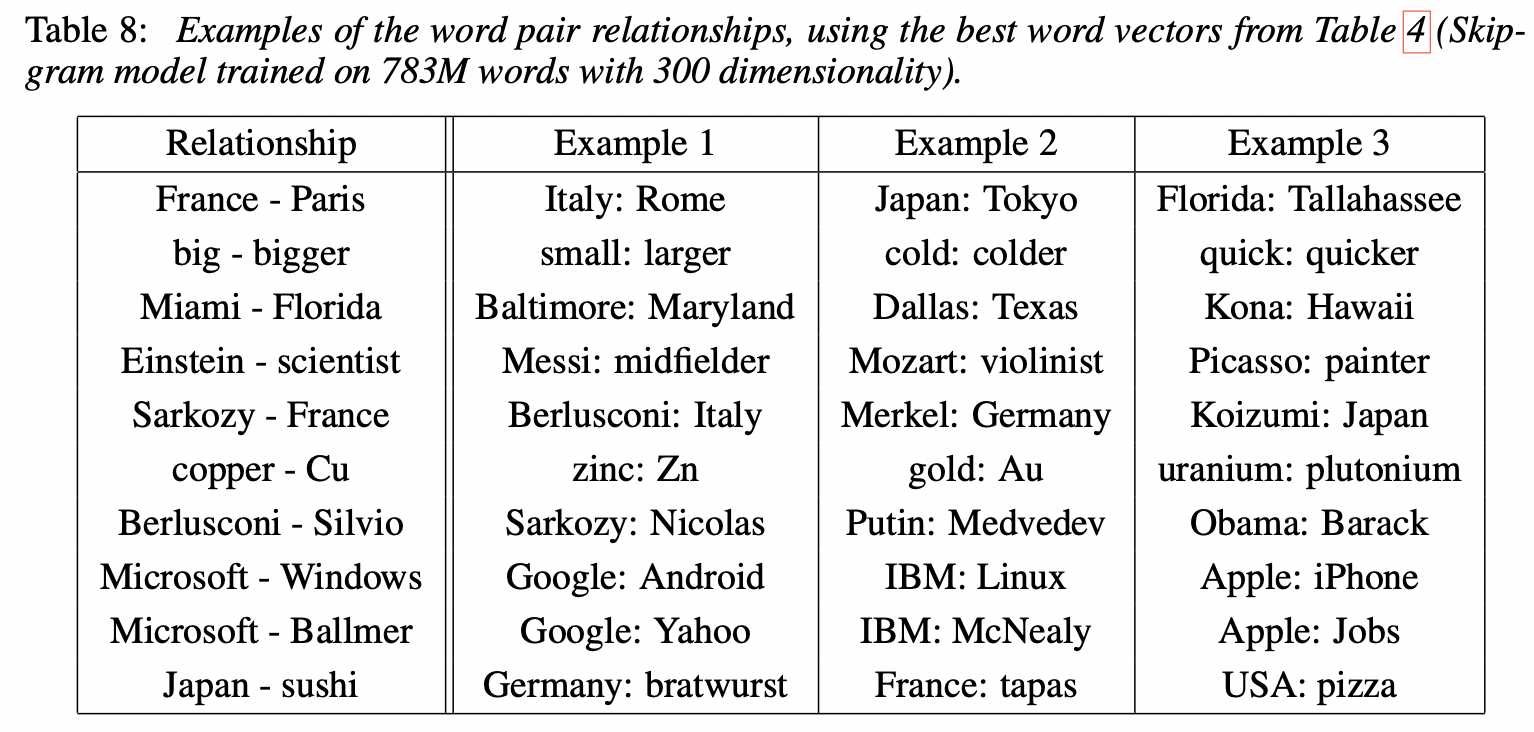
Examples of the Learned Relationships
실험을 통해 학습한 단어들의 의미 관계는 다음과 같다.
Conclusion
저자는 간단한 방법의 새로운 단어 벡터의 표현 방법으로 의미적, 구문적인 성능이 뛰어난 모델 연구를 하였다.
이 논문에 대한 결과는 word2vec으로 구현이 되어있는데 CBOW, Skip-gram에 대한 구체적인 이해 없이도 단어를 벡터화하여 다양한 NLP 어플리케이션에 응용할 수 있다는 점에서 저자들이 의도한 연구 목표가 잘 이행되고 있는 듯 하다. 논문을 작성하던 시기에는 CPU로 실험을 하였는데, 이 논문은 벡터 연산에 매우 큰이점이 있는 GPU의 등장과 함께 자연어처리 연구에 큰 이정표가 되는 연구인 듯 하다.
CBOW, Skip-gram은 모든 단어에 대한 결과를 구하므로 단어의 양이 많아지는 경우 연산량이 그대로 증가하는 속성이 있다. 대규모 데이터에 단점이 있기 때문에 이를 개선하기 위한 후속연구들이 있다.
다음 글에서는 word2vec을 구현한 gensim 라이브러리 사용법을 간단히 정리해보자.



