Attention is all you need - 4 (모델 학습, 결론)
2022. 9. 27. 22:42
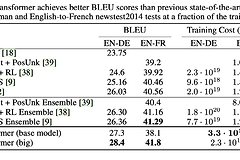
Training Training Data and Batching WMT 2014 4.5백만개의 영어-독일어 문장 쌍으로 데이터 셋을 학습하였다. 문장을 기존에 있는 단어를 분리하는 방법인 byte-pair 인코딩을 이용해 37,000토큰으로 구분하였다. 영어-프랑스어 학습에는 36백만 문장으로 구성된 대규모 WMT 2014 영어-독일어 데이터셋을 사용해 32,000 word-piece 단어로 나누었다. 문장 쌍은 시퀀스 길이를 조절하여 함께 배치처리 하였다. 각 배치는 대략적으로 25,000개의 source 토큰과 25,000개이 target 토큰으로 구성했다. Hardware and schedule 실험을 위해 NVIDIA P100 8개로 구성된 하나의 머신을 사용했다. 한번의 step은 대략 0.4초..


