ICML 2021 논문이다.
트랜스포머가 자연어처리 태스크에 적용되어 기존 모델들이 가진 순차적인 처리, 장거리 의존성, 병렬처리 등의 한계를 해결하고 있었다. 딥러닝 연구에서 어떤 모델이 비전이나 자연어처리 같은 태스크에 자리를 잡으면 태스크를 바꿔서 적용하려는 시도가 있는데, 비전트랜스포머(ViT) 연구는 트랜스포머를 비전 태스크에 적용하고자 진행되었다.
구조는 꽤나 간단하다.
이미지를 고정된 크기의 패치로 나누고 각 패치를 layer를 추가하여 평탄화(flatten)한다. 이미지는 rgb 멀티채널 이기때문에 각 채널을 concat하고 선형사상(mlp)하여 트랜스포머에 입력가능하도록 한다. 그리고 위치 관계 추출에 능한 CNN과 구조가 다르기 때문에, 위치정보인 position embedding을 덧붙인다. 마지막으로 학습가능한 classification class 토큰을 붙인다. 모델은 분류에 사용하기 위해 트랜스포머의 인코더 부분을 사용한다.

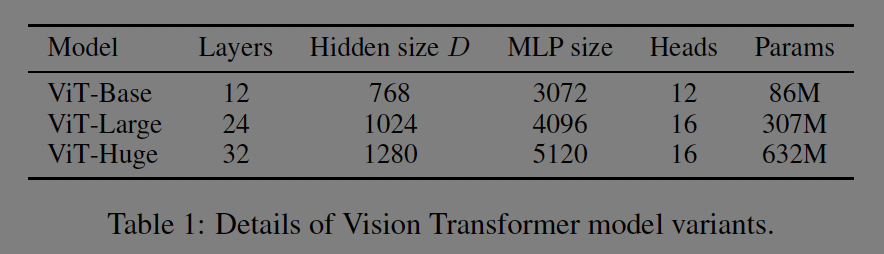
모델은 BERT와 같이 크기에 따라 base, large, huge로 나누고 모델의 하이퍼파라미터는 표1과 같다. 모델의 뒤에는 패치 크기가 붙어 구분한다.
실험 결과는 표2와 같다. 대규모 데이터셋인 JFT에서 huge/14 모델로 학습한 것이 여러가지 벤치마크에서 성능이 가장 좋았다. ResNet 모델보다 학습에 필요한 연산량도 훨씬 경제적이었다. 세번째 칼럼의 이미지넷 21k 데이터셋에서도 꽤나 괜찮은 성능을 보인다.

VTAB은 natural, specialized, structured로 나뉜 19개의 태스크를 실험하는데, 기존 SOTA 모델들보다 세분화하여 봐도 성능이 가장 낫다.

그림 3을 보면 ViT는 데이터 양이 적고 large 모델로 학습한 때에는 BiT보다 성능이 낮지만 데이터셋이 더 많아지면 성능이 역전된다.

사전학습한 모델을 클래스별로 5개씩 few shot 학습한 이미지넷 결과에서도 이와 비슷한 양상을 확인할 수 있다. JFT 데이터셋중 일부인 10m, 30m 등에서는 Resnet 기반 모델의 성능이 더 좋지만 100m 이상이 되면 ViT의 성능이 추월한다.

계산량과 성능을 비교하는 실험은 그림 5에 담고 있다. ViT는 average-5 셋에서 ResNet보다 대략 2배에서 4배정도 계산 효율적이다. 하이브리드 모델은 살짝 ViT를 앞서지만 모델 크기가 커질수록 차이는 줄어든다. 저자들의 실험 규모에서는 ViT는 saturation되지 않아 더 규모를 키울 여지가 있다.

ViT는 이미지 데이터를 어떻게 처리하는지 모델 내부의 표현을 살펴보았다. 그림7의 좌측 그림은 평탄화된 뒤 학습된 첫번째 층이다. 가운데 그림은 위치 임베딩 사이의 유사도에 대한 그림인데, 그림 안에서 가까운 패치끼리 유사도가 높은 것을 알 수 있다. row-column이 같은 경우 유사도가 높은 경향이 있다. 더 큰 그리드에서는 사인파 함수처럼 보이기도 한다. 위치 임베딩은 2차원 이미지의 구조를 학습하려는 것이다.

Self-attention의 역할은 어떤 것일까? 자연어 처리에서 Transformer가 강점이 있는 것이, 문장 전체의 global한 구조를 잘 파악한다는 것이다. CNN 모델처럼 모델 구조에서 오는 inductive bias는 떨어져도 패치로 이루어진 이미지 전체에서 통합적인 정보를 알아내려 했다. 이 연구에서는 attention weights를 기반으로한 attention distance라는 용어로 CNN의 수용영역(receptive fields)와 유사한 개념을 그림7의 우측 그림에서 확인한다. 그림 6에서 모델은 이미지 분류와 의미적(semantically)으로 관련 깊은 영역에 집중한다는 것을 보인다.
그림 7의 우측을 보면 낮은 층에서는 head들이 다양한 거리에서 분포하고 있지만 층이 깊어질 수록 거리가 커진다.

Reference
https://arxiv.org/abs/2010.11929
'papers > Vision' 카테고리의 다른 글
| Unsupervised Visual Representation Learning by Context Prediction (0) | 2025.03.07 |
|---|---|
| U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2025.02.19 |
| Fully Convolutional Networks for Semantic Segmentation (0) | 2025.02.13 |
| You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.12.18 |
| Deep Residual Learning for Image Recognition (0) | 2024.12.10 |



