Attention mechanism에 대해 이해를 더하고자 찾아 본 논문이다.
조경현 교수님이 저자로 포함되어 있고 2015년 ICLR에 발표되었다.
기계번역(NMT)에서는 하나의 신경망 학습을 고도화 하는 방식으로 발전했다. 입력 문장을 고정된 길이의 벡터로 인코딩하고 번역문을 디코드하는 인코더-디코더를 활용하고 있다. 이 논문에서는 고정된 길이의 벡터(fixed-length vector)가 기본적인 인코더-디코더의 성능 향상을 가로막고 있다고 추측한다. 고정된 길이의 벡터로 입력 문장을 압축하는 방법은 문장의 길이가 길어질 경우 성능 저하가 크기 때문이다.
이를 해결하기 위한 방법으로 입력 문장(source sentence)에서 예측을 위한 타겟 단어(target word)와 관련성이 높은 부분을 자동으로 찾는 방법으로 제시한다. 현재 시점 논문에 쓰인 이 방법(alignments)은 attention mechanism으로 불리고 이에 기반한 방법론은 딥러닝 학습에 주류 학습법으로 사용되고 있다.
Bidirectional RNN을 사용하는 이점은 순방향과 역방향 학습을 통해 문장에 대한 이해를 높일 수 있는 점이다. 우리가 언어를 사용할때 이전 단어들을 통해 타겟 단어를 예측할 수 있지만, 타겟 단어의 다음 단어들로 이전의 단어를 예측하는 것도 가능하고 두 방법을 보완적으로 사용하는 것이다.
저자는 논문에서 제안하는 방법을 수식으로 설명한다.
y_i를 구하기 위한 함수 g는 (y_i-1, s_i, c_i)를 매개변수로 한다. 수식1이 우항에 있는 s_i는 time i의 RNN hidden state이고 수식2를 통해 얻는다. i시점의 hidden state는 전 시점의 hidden state, 전 시점의 출력 확률, i 시점의 context vector를 통해 얻는다.
수식1, 수식2의 파라미터인 c_i는 수식3으로 구한다. 번역된 문장에서 출력 단어 i의 위치가 입력문장의 j 시점 주변에 있을 가능성이 얼마나 되는지를 계산하는 alignment model score를 모든 입력 시점에 대해 구하고 softmax를 거쳐 확률로 나타낸다. figure3 (a)를 보면 이해에 도움이 되는데, 단어별로 순서가 다르지만영어의 European과 불어의 단어가 문장에서 나타난 순서가 다르지만 같은 의미를 뜻한다는 것을 알 수 있다. 저자는 alignment model을 파라미터화하여 학습시켰다.
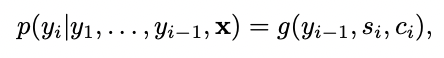



figure1을 통해 수식을 직관적으로 이해 할 수 있다.
양방향 RNN을 사용하고 있고, y_t를 얻기 위해 어느 단어에 집중해야하는 지를 계산하기 위해 출력의 t시점과 입력의 모든 시점의 점수를 계산하고 있다. target word 계산에는 이 가중합과 이전 시점의 hidden state를 이용하는 것을 그림을 통해 알 수 있다.


실험 결과는 다음 그림과 같다. 기존 인코더-디코더 모델에 비해 30단어, 50단어에서 큰 성능향상이 있었다.
특히 RNNsearch-50에는 50단어를 넘어 60단어 수준에서도 BLEU score가 유지되었다.
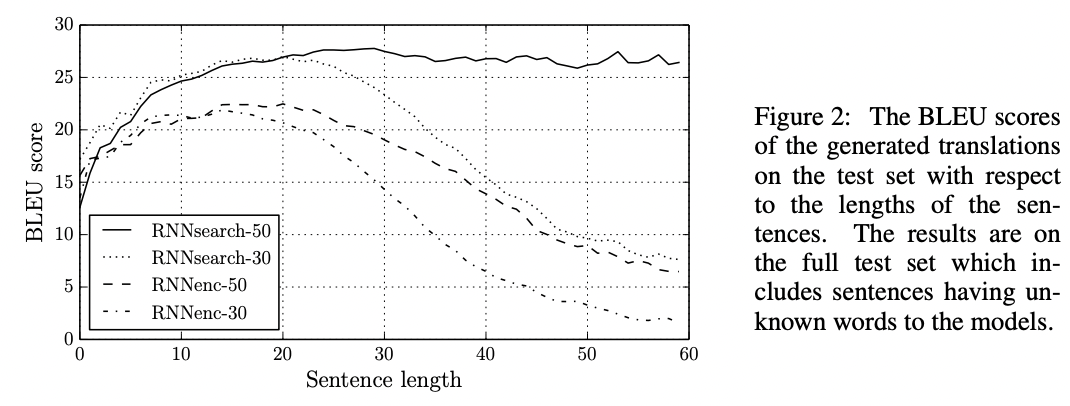
실험에 대한 구체적인 사항은 논문 원문을 참고바랍니다.
설명은 하단에 참조한 허민석님 유튜브 [딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델이 가장 잘 이해되었습니다.
Reference
'papers' 카테고리의 다른 글
| Attention is all you need - 4 (모델 학습, 결론) (0) | 2022.09.27 |
|---|---|
| Attention is all you need - 3 (모델 아키텍쳐2) (1) | 2022.09.21 |
| Attention is all you need - 2 (모델 아키텍쳐1) (1) | 2022.09.21 |
| Attention is all you need - 1 (요약, 개요, 배경) (1) | 2022.09.19 |
| Exploration in Recommender Systems (0) | 2022.01.13 |

