이 논문은 CNN이 왜 잘 작동하는가, 어떻게 성능을 개선할 수 있는지에 대해 연구한 것으로 2013년에 발표되었다.
저자들의 이름 앞자를 따서 ZFNet으로 부른다. 피쳐 추출시 어떤 원리로 동작하는지를 이해할 수 있도록 시각화 기법을 도입하였다. 그리고 이미지넷2012 대회에서 우승한 Krizhevsky의 AlexNet보다 나은 성능의 모델을 제시한다.
저자들은 피쳐의 활성화를 역으로 픽셀 공간으로 사영(project)하는 시각화방법인 multi-layered deconvolutional network(deconvnet)을 제안한다. 모델의 일부 층을 제거(ablation)하는 실험을 통해 모델의 세부 계층이 성능에 어떤 영향을 미치는지 실험한다. 그리고 이미지의 일부분을 가리는 실험을 통해 특정 부분이 가려지는 것이 성능에 영향을 미치는지 (분류기의 민감도)를 측정한다.
Deconvnet은 fig1의 좌측에 나타난다. CNN의 역으로 대략적인 복구가 진행된다. 최대 풀링시에 위치를 남겨(switches) 본래의 위치를 복구하는 Unpooling, rectification, 상하좌우로 convolving하는 filtering을 거친다.

Fig2에서는 저자들의 모델은 학습한 활성화 정도를 보여주는 top9개의 시각화자료가 나온다. 피쳐를 픽셀 공간으로 사영한 것(9개)은 주어진 피쳐맵을 활성화시키는 다른 구조를 나타내기 때문에 입력 변형(input deformation)에 대한 불변성을 나타낸다. (시각화 자료에서 활성화 된 부분이 입력 이미지의 특징을 나타낸다 정도로 이해했다). 시각화에 따라서 원본 이미지를 처무했다. 학습이 진행될수록 각 이미지에서 구분이 되는 부분(discriminant structure)에 집중하기 때문에, 깊은 층의 시각화는 더 큰 변형이 나타난다.

피쳐를 픽셀로 사영하여 시각화 한것은 샘플링이아니라 피쳐에서 활성화 정도가 큰 부분을 재생성(reconstruct)한 것이다.

fig4를 보면 층이 깊어질 수록 더 많은 epoch의 학습이 필요함을 알 수 있다.
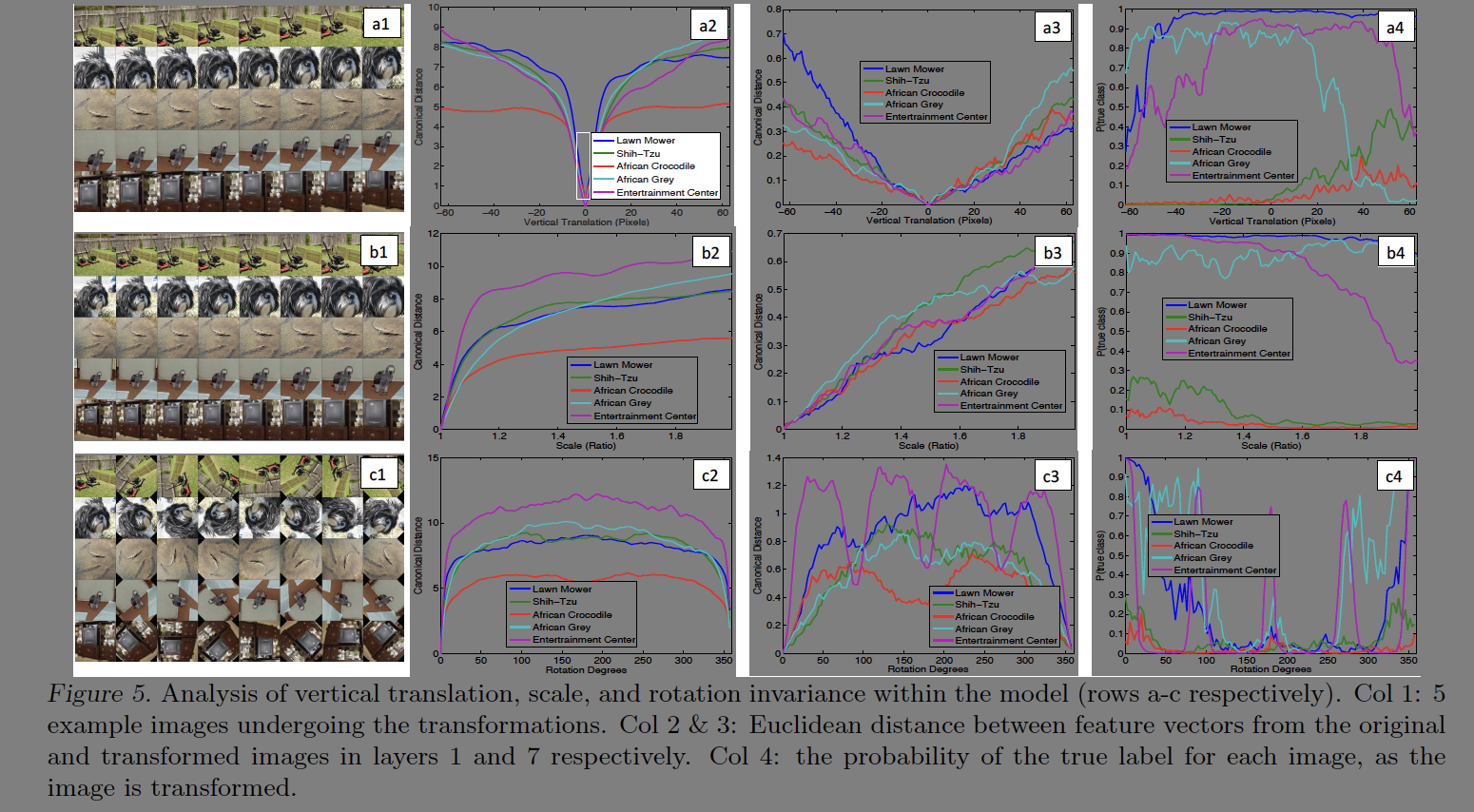
fig5에서는 샘플 이미지를 회전(rotation), 화면 아래로 내리기(vertical translation)하고 스케일링(scale)해서 피쳐벡터의 변화를 살펴보았다. 얕은 층에서 약간의 변화가 영향이 있었지만 층이 깊어질수록 영향이 줄었다. 실험 결과는 이미지에서 확인할 수 있다.

fig6에서는 얕은층에서 AlexNet과 비교한다. 2층에서 aliasing artifacts를 해소하기 위해 stride(4 to 2), 필터 크기(11x11 to 7x7)에 변화시켰는데 피쳐가 더 구분이 잘되고 dead 부분이 없다. 분류 성능도 개선되었다.
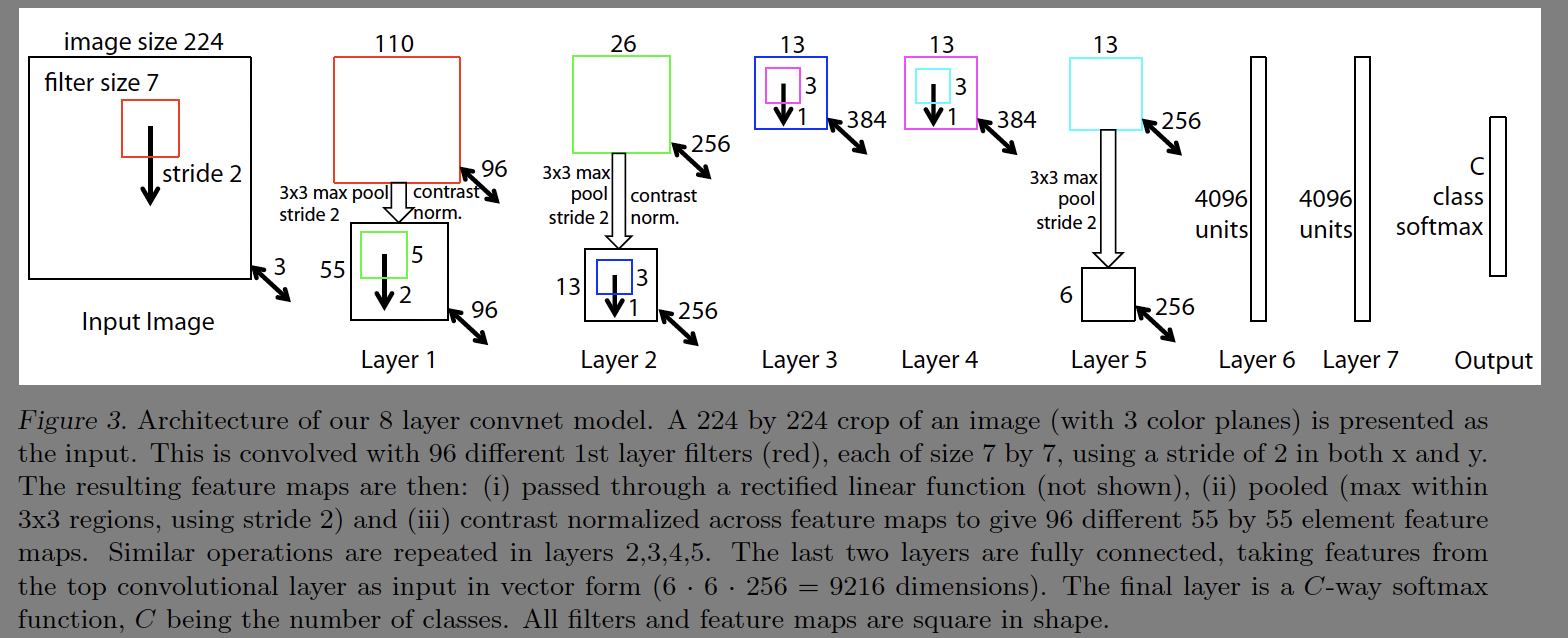
저자들이 제안하는 모델은 fig3과 같다. AlexNet과 거의 유사하다.
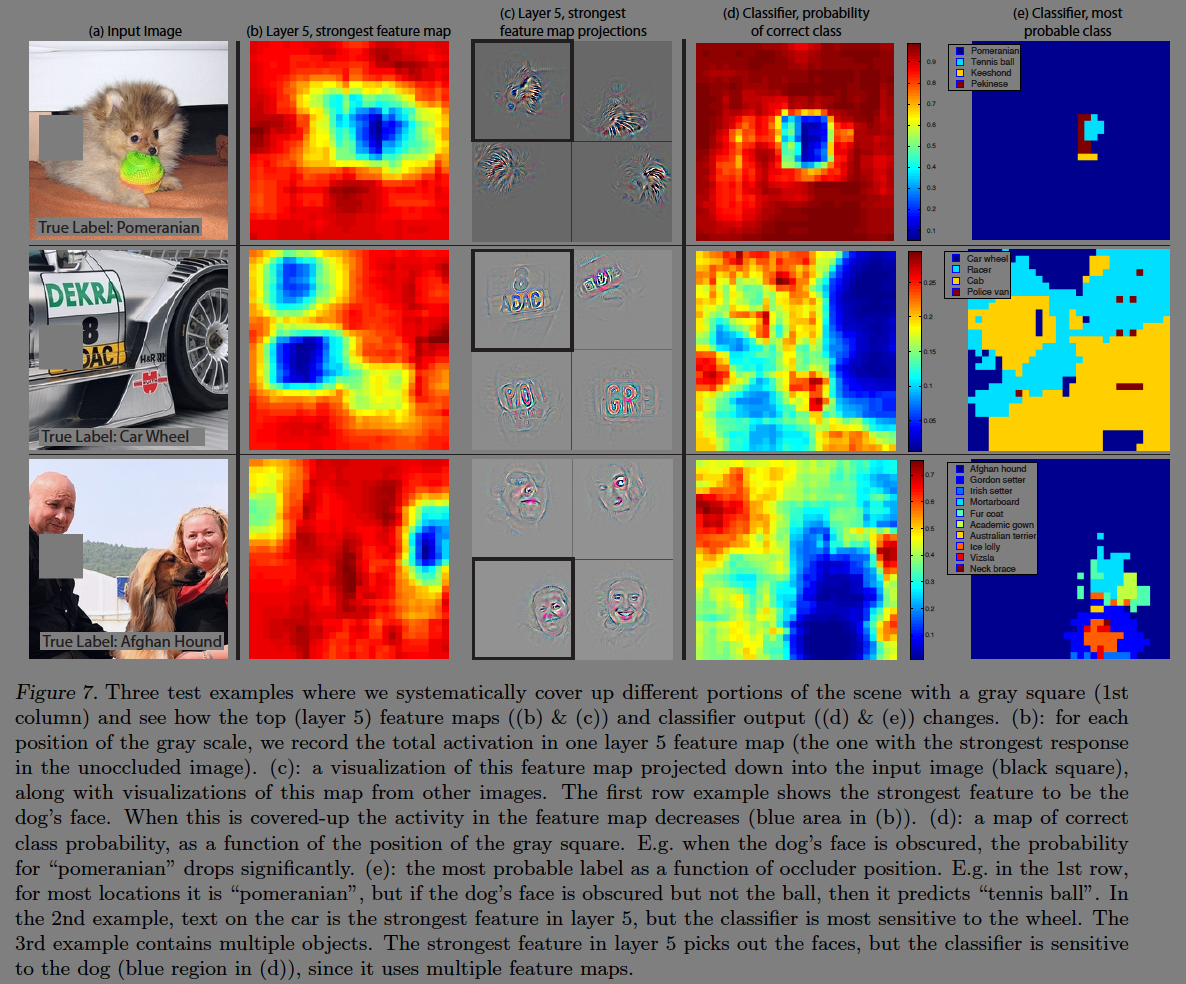
이미지 분류 접근법에서 모델이 객체의 위치를 이해하는지 혹은 주변 정보를 확인하는지를 궁금해하게 된다. Fig7은 이미지에서 특정 부분을 회색 네모로 처리하여 분류기의 분류 결과를 측정하였다. 객체가 제외되었을때 클래스 분류 확률이 유의미하게 떨어지는 것기 때문에 모델은 객체를 이미지에서 로컬라이징 하는 것을 알 수 있다. 이 실험을 통해 이미지의 구조(image structure)는 피쳐맵에 영향을 주는 것을 확인할 수 있다.
입력이미지(a)의 피쳐맵에서 활성화 정도가 강한 부분은 (b)에 나타난다. 피쳐맵을 입력 이미지로 복구한 것은 (c)에 나타난다. 세번째 줄의 이미지는 사람, 개 얼굴등 다양한 이미지가 나타나고 가장 강한 특징은 여성의 얼굴이지만 CNN은 여러개의 다양한 피쳐맵을 사용하기 때문에 개로 분류하였다.
저자들은 딥러닝 모델이 서로 다른 이미지에서 얼굴에서 눈이나 코 같은 특정 객체를 판단하는 매커니즘이 있는지 확인하는 실험을 하였다. Fig8에서 저자들은 랜덤하게 5개의 개 정면 사진을 가지고 각 이미지에서 특정 부분을 제외하였다(mask out 왼눈, 오른눈, 입, layer5과 layer7사용). 원본데이터와 제거 이미지의 거리를 측정하였다 (결과는 Table1). 이미지 쌍의 Hamming distance를 측정하였고 낮은 값은 마스킹 작업으로부터 더 큰 일관성(consistency)를 나타낸다. 임의 부분을 제거한 것 보다 이미지로 인식할 수 있는 특정 부분을 제외한 것이 더 점수가 낮게 나왔다. Layer 7에서는 모델이 개들의 종도 분류하기 때문에 random 분류와의 차이가 적다.

모델의 특정 층을 제거하거나 맵의 크기를 변화하여 실험한 결과와 여러 데이터셋의 결과는 원문의 Table3에서 확인할 수 있다.
Reference
'papers > Vision' 카테고리의 다른 글
| Learning Deep Features for Discriminative Localization (1) | 2024.11.30 |
|---|---|
| Fast R-CNN (0) | 2023.10.15 |
| OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks (0) | 2023.04.06 |
| Rich feature hierarchies for accurate object detection and semantic segmentation (0) | 2023.03.02 |
| Going deeper with convolutions (1) | 2023.02.22 |



