이 논문은 RNN(순환신경망) 계열 모델을 비교한 논문이다. 전통적인 tanh 모델과 Gating mechanism을 사용한 LSTM(Long Short-Term Memory), GRU(Gated Recurrent Unit)를 비교한다. Polyphonic 음악 모델링, 스피치 신호 모델링 데이터를 통해 학습속도, 에러율등을 비교했다.
RNN의 구조및 수식은 간단하므로 생략한다.
이번 글을 통해 LSTM과 GRU의 아키텍처를 이해해보자. 수식과 다른 블로그에서 첨부한 그림을 같이보면 이해가 쉽다.
LSTM은 장기 의존성 문제가 있는 긴 시퀀스의 작업을 잘 학습하고 GRU는 최근(2014년)에 기계 번역의 문맥 학습에 사용되었다. 1997년 처음 제시된 모델이고 구조에 작은 변형들이 있어 저자는 2013년에 제안된 모델을 구현하였다. Input gate, forget gate, output gate가 존재한다. Cell state와 hidden state도 알아야 하는 개념이다.
LSTM과 GRU의 그림은 아래와 같다.
논문의 그림은 이해가 직관적이지 않으므로 다음 그림을 보고 수식을 보면 이해가 쉽다.
(그림과 수식이 연결이 안되면 reference의 블로그에서 수식을 같이 확인하는 편이 낫다.)
LSTM에서 Cell state는 장기 기억을, hidden state는 단기 기억을 저장한다. forget, input, output gate에서는 신경망을 거친 후 pointwise 곱을 한다. GRU는 LSTM의 간소화 버전으로 Cell state가 없이 hidden state만 존재하여 계산이 간결하다.

그림의 범례에 있는 pointwise operation은 chatGPT는 다음과 같이 설명한다. 자료 구조에서 같은 위치끼리 하는 연산을 의미한다.

LSTM의 수식은 다음과 같다.
j번째 LSTM 유닛은 t시점의 기억을 cell state로 유지한다. t시점의 hidden state는 output gate와 cell state에 활성화함수 tanh를 거친 값들을 곱해서 구한다.
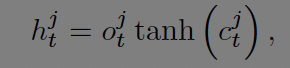
output gate는 메모리 노출의 양을 조절한다. 활성화 함수 입력들은 각자 다른 가중치 가 곱해 진다. t시점의 입력과 diagonal matrix를 곱한 cell state, t-1시점의 hidden state를 더한 뒤 logistic sigmoid 활성화함수를 거친다.
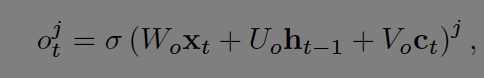
Cell state는 현재의 기억을 일부 잊고 새로운 기억을 더하여 구한다. 아래 수식의 우변에서 첫항은 이전 시점(t-1)을 얼마나 잊을 것인지 두번째 항은 새로운 기억을 얼마나 할것인지에 대한 부분이다.
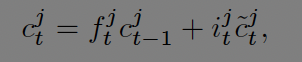
새로운 기억은 t시점의 입력과 t-1시점의 hidden state 값을 더한 뒤 활성화 함수 tanh를 거친다.
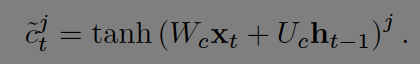
현재 기억이 얼마나 잊혀질지는 forget gate에서 결정되고 새로운 입력을 얼마나 기억할지는 input gate에서 결정된다.
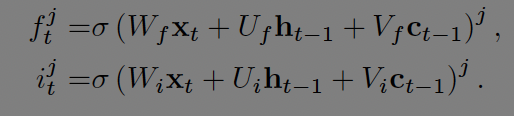
GRU의 수식은 다음과 같다.
t시점의 hidden layer(출력)는 t-1시점과 t시점의 입력의 선형 보간을 통해 결정된다. 블로그에서 가져온 그림과 논문의 수식에서 1-z와 z가 반대로 되어있는 듯하다.
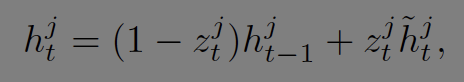
Update gate z는 얼마나 갱신할지를 결정한다. 상단의 GRU 그림에서 보면 z를 통해 input과 forget을 제어하는 것을 알 수 있다.
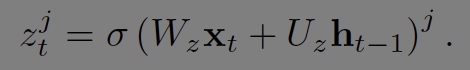
reset gate r을 통해 t-1 시점의 hidden 정보를 통제한다.
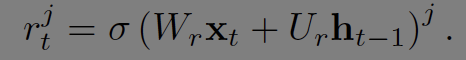
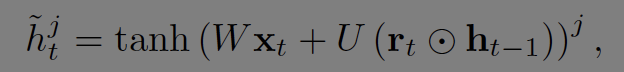
논문에 있는 LSTM, GRU의 아키텍처는 아래와 같다.
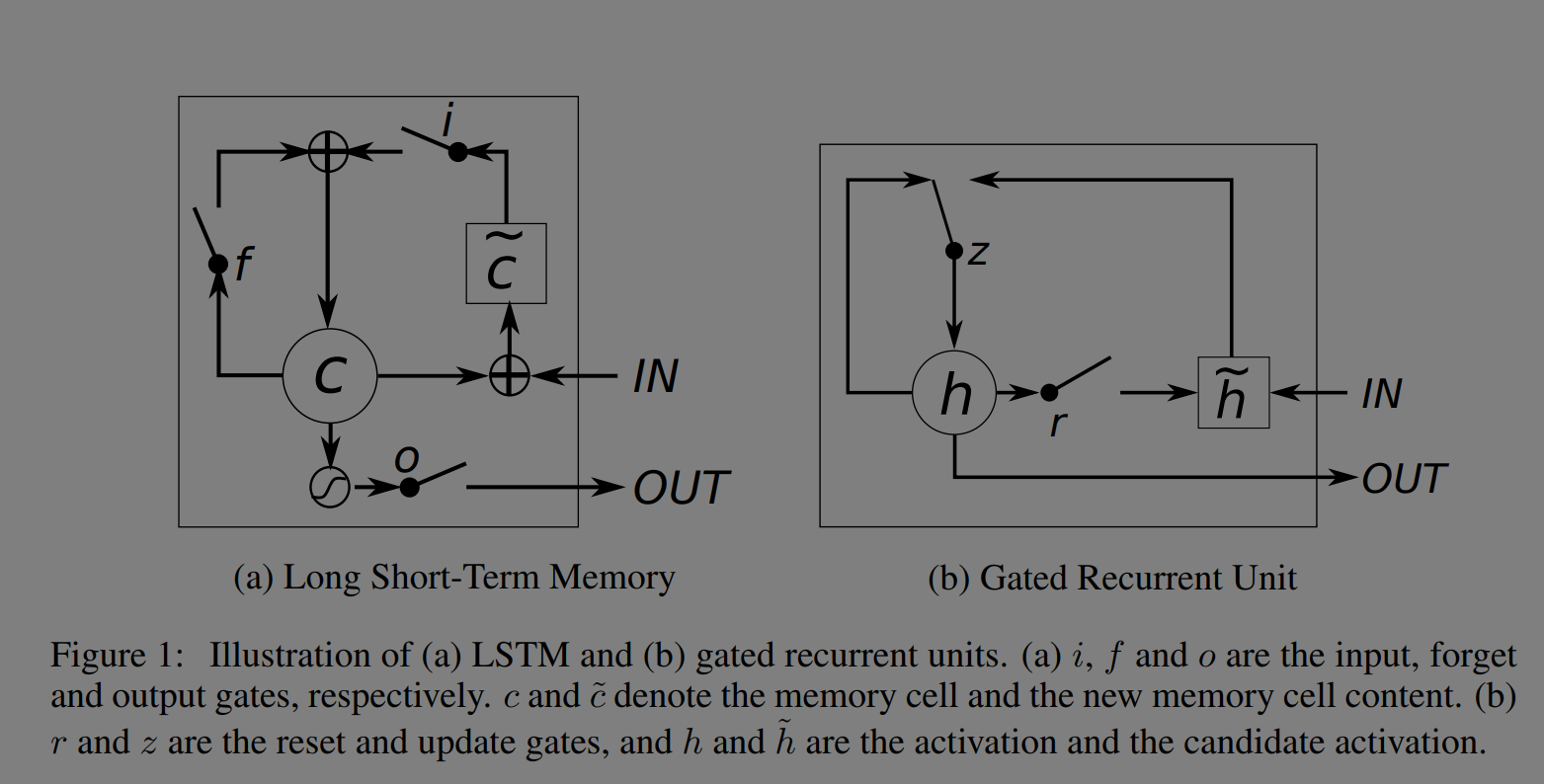
LSTM, GRU이 RNN과 다른 것은 t시점에서 t+1시점으로 업데이트 할 때 추가적인 컴포넌트가 있어 스텝이 길어짐에도 기존 정보를 유지하는데 강점이 있는 것이다. RNN은 매 스텝마다 새로운 정보로 overwritten 되지만 LSTM, GRU는 이전 스텝의 정보를 유지한다. 이를 통해 vanishing gradients를 회피한다. 그리고 새로운 입력이 들어올때 LSTM은 forget gate에서 독립적으로 더하지만 GRU는 정보의 흐름을 독립적이지 않게 관리한다.
두 순환 신경망 구조의 좋고 나쁨을 가리기는 어렵다.
논문 원문에서 모델별 비교에 대한 실험을 확인할 수 있다.
Reference
https://arxiv.org/abs/1412.3555
https://www.youtube.com/watch?v=5Ar1aN9gceg // 설명 참 잘하신다.
https://excelsior-cjh.tistory.com/185
(http://colah.github.io/posts/2015-08-Understanding-LSTMs/)



