이 논문은 공간적인 맥락(spatial context)을 이용해 시각 표현(visual representation)을 학습했다. 레이블이 없는 대규모 이미지 집합에서 랜덤한 쌍의 패치를 각 이미지에서 추출해 콘볼루션 네트워크를 학습하여 첫번째 패치에 대한 두번째 패치의 위치를 예측하였다. 이 태스크를 잘하기 위해서는 객체와 세부 사항을 학습시켜야 했다.
저자들은 이미지 내의 맥락을 이용한 특징 표현이 이미지 전체의 시각적인 유사성을 파악할 것이라는 가설을 증명한다. 예를들어 Pascal VOC 2011 탐지 데이터셋에서 고양이, 사람, 새 같은 객체를 비지도로 검출하는 작업을 했다. 더욱이 저자들의 모델은 RCNN 프레임워크에서도 사용 가능해 랜덤하게 초기화된 콘볼루션보다 성능 이점이 있다.
연구 당시에는 정답이 없는 데이터에서의 비지도 방법은 완전한 크기의 실제 이미지에서 의미있는 정보를 추출하지 못하고 있었다. 아무런 객체의 레이블이 없을때 객체를 포착하기 위한 목적함수(objective function)을 설정할 것인지를 RQ로 잡은듯하다. 그렇지만 당시에도 텍스트 도메인에서는 문맥이 표현을 학습하는데 중요한 자원이라는 연구들이 있었다. 대규모의 코퍼스(corpus)에서 단어들을 피쳐 벡터와 매핑하는 학습을 진행하는 것인데, 주어진 단어의 전후의 문맥에서 단어를 예측하는 것이다. 이는 비지도 문제를 자기 주도(self-supervised) 방법으로 전환시킨다. 주어진 단어 주변의 단어들을 학습하는 것이다. 문맥 예측 태스크는 pretext라 하고 좋은 단어 임베딩을 학습하는 것이다.
저자들 논문의 목적은 패치의 문맥을 예측하는 작업을 포함해 유사한 self-supervised 학습을 이미지 데이터에 적용하는 것이다. 저자들은 랜덤하게 8개중 하나의 쌍을 샘플링하는데 각 쌍은 원래 위치에 대한 정보가 없다. 저자들의 알고리즘은 상대 쌍에 대한 상대적인 위치를 추측한다. 저자들의 가설은 이 태스크를 잘 해내는데에는 전체적인 풍경과 객체들을 이해할 것이라는 것에 바탕한다. 즉 이 태스크에서의 좋은 표현(good representation)은 객체를 추출하고 그들의 상대적인 위치를 추론(reason)하는 것이 필요하다. 객체는 여러가지 부분(parts)로 이뤄져있고 각 부분마다 공간적인 특징(spatial configuration)이 있을 것이다. 저자들은 시각 표현(visual representation)의 결과가 객체 검출과 시각 데이터 마이닝(visual data mining, object discovery)에 효과적이라는 것을 증명해 저자들의 표현이 이미지를 일반화한다는 의미를 발견했다.

저자들은 pretext 방법을 도입한다. 특히 텍스트 도메인에서 효과를 내는 skip-gram의 방법을 적용한다. 단어 하나를 통해 앞과 뒤의 n개를 예측하는 방식으로 visual fill in the blank 태스크라고 하였다. 그러나 아주 낮은 단위 특징(low level feature) 잘 포착하지 못한다. 이를 해결하기 위해 이미지의 지역(region)을 둘러싼 근접한 지역(transitive nearest neighbors)들을 컨센서스 보팅(consensus voting) 방식으로 예측하였다.
같은 의미를 가진 물체에서도 다양한 양상이 있기 때문에 픽셀을 예측하는 것은 단어를 예측하는 것보다 어려운 작업이다. 텍스트 도메인에서 흥미로운 아이디어는 단순한 예측 태스크를 구분(discrimination) 태스크로 변경하는 것이다. 이 경우 pretext 태스크는 텍스트에서 단어가 랜덤하게 대체된 스니펫에서 텍스트의 true snippet을 구분하는 것이다. 이를 확장하자면 진짜이미지와 이미지 중 일부 패치만 랜덤하게 대체된 이미지를 구분하는 것이다. 이 연구에서는 난이도를 높여 한개 이미지에서 여러개의 패치 중 샘플링한 것을 분류한다(fig 2).
이미지에서 비지도학습을 하는 것은 hand-crafted features와 다양한 군집화를 이용해 객체의 카테고리를 발견하는 것을 목적으로하는데 이 방법들은 모양(shape) 정보를 잃는다. 표현(representations)이 더 모양 정보(윤곽 등)를 유지하기 위한 하위 작업들이 있었다. 일부는 클러스터링 분석에 사용하는 유사도를 정의하는 접근방법이 있고 Geometry가 이미지들의 연결을 확인하기 위해 사용되기도 하지만 변형가능한(deformable) 객체에서 적용이 어렵다.
결과적으로 저자들의 연구는 패치 마이닝(discriminative patch mining)과 관련이 있는데, 약한 감독(weak supervision)을 객체 감지의 수단으로 강조한다. 이 방법은 객체의 전체나 장면을 학습하기 전에 일종의 pretext 태스크처럼 부분들에 해당하는 패치의 표현을 학습하는 것의 중요성을 이용하는 것이다.
저자들은 pretext 태스크로 이미지 표현을 학습하고자 했다. 즉 이미지 안의 패치들의 상대적인 위치를 예측하는 것이다. 모델은 CNN을 사용했다. 두개의 패치를 모델들에 입력하고 각 8개 지역의 확률을 출력한다 (fig 2). 궁극적으로는 다른 이미지들에서 시각적으로 유사한 패치들이 가까운 임베딩 공간에 위치하는 것이 목적이다.
저자들은 먼저 2개의 모델을 학습하고 나중에 통합하는 알렉스넷 스타일의 구조(late fusion)를 사용한다. 6번째 층이전까지 각 콘볼루션 층의 가중치는 양쪽에서 연결(tie)된다. 이는 연결된 추론(joint reasoning)에 한계가 있기 때문이다. 저자들은 패치별로 나뉘어져서 의미 추론을 하기 원했기 때문에 패치별로 모델을 나눈 것이다.
pretext 태스크를 디자인할때 네트워크가 원하는 정보를 trivial solution을 이용하지 않고 추출해야한다. 이 연구에서는 경계의 패턴이나 질감들이 패치들끼리 연속되는 경우가 shortcut이 될 수 있다. 고로 상대적인 위치를 예측하는 작업에 있어 패치사이에 일정 간격(jitter)을 두는 것이 중요하다(7 pxls). 렌즈의 왜곡에 의한 Chromatic aberration도 trivial solution의 예이다.

네트워크는 렌즈에서 절대적인 위치를 학습할때 상대적인 위치를 찾는것은 trivial이 된다. 이를 방지하기위해 두가지 처리를 하는데, RGB 공간에서 초록과 마젠타 색의 축의 projection행렬을 뺀 다음에 모든 픽셀에 곱한다. 대체 접근법으로는 각 패치에서 랜덤하게 3칼라 채널에서 2개를 뺀다(color dropping). 드랍된 칼라를 잔여 채널의 가우시안 노이즈로 대체한다. 결과적으로 두 방법은 비슷한 결과가 나온다.
실험을 위해서 레이블이 제거된 이미지넷 2012 학습 데이터(1.3M)을 사용하였다. 우선 모든 이미지를 비율을 유지한채 150-450k 픽셀크기로 리사이징했다. 패치 크기는 96 by 96으로 설정하고 계산 효율성을 위해 그리드 같은 패턴만 샘플링했다. 8개의 패치 페이링에 사용하고, 샘플링하는 패치는 48픽셀의 간격을 두었다. 그리고 모든 패치는 -7~7픽셀의 간격을 두고 간단하게 이동하였다(jitter는 각 패치별로 흔들거림을 주는 것인듯). 패치에 대해 mean subtraction, 사영, 색 드롭, 랜덤하게 다운샘플링 후 업샘플링을 통해 pixelation(??)의 강건성을 도모했다.

SGD를 사용할때는 예측 성능이 퇴화되었다. Fc6과 fc7의 활성화함수가 0이 되어 최적화가 새들포인트(saddle point)에 빠져 입력의 낮은 층들을 무시하게 되었음을 의미했다. 이에 대응하기위해 저자들은 배치놈을 적용하고 높은 모멘텀 값(0.999)을 이용했다.
실험에는 네트워크가 의미적으로 유사한 패치를 학습할 수 있는지 입증했다. 우선 VOC 2007 객체탐지 데이터를 이용해 사전학습(pre training)에 활용. 두번째로 시각 데이터마이닝 평가하여 레이블이 없는 이미지 집합에서 객체 클래스들을 발견하는 것이다. 최종적으로는 레이아웃 예측(pretext task) 성능을 분석하고 얼마나 더 학습할게 남았는지 평가했다.

어떤 패치가 유사한 패치일까? 저자들은 fc6에서 표준화된 상관관계를 이용해 근접한 패치(nearest neighbor)를 찾았다(fig 4). 알렉스넷의 fc7 피쳐와 저자들의 구조를 이용한 훈련되지 않은fc6층과도 비교했다. 제안된 네트워크가 의미적으로 유사한 패치를 잘 매치한다. 학습하지 않은 콘볼루션 넷도 잘하긴 한다..
저자들은 초기 NN 실험에서 몇몇 패치는 유사한 왜곡(aberration)이 있어 콘텐츠 의미와 상관없이 절대적인 위치(location)를 이용해 패치 매치를 하기도 한다. 이 현상을 더 알아보기 위해 이미지넷에서 샘플된 패치의 좌표의 회귀모델을 학습시켰다. 전반적인 정화도는 높지 않았지만 어떤 이미지에서 놀랍게 성능이 좋았다. 상위 10%에서는 평균 RMSE가 .255였다. 투영을 적용한 실험은 상위 10% 에러를 .321로 증가시켜 위치 예측 성능이 낮아졌다.
이전의 작업들은 Pascal VOC 챌린지에서 이미지넷 사전학습과 파인튜닝이 성능향상에 꽤나 좋음을 알아냈지만 비지도 사전학습(unsupervised pretraining)에는 효과가 없었다. 저자들은 RCNN 방법을 사용했다. RCNN에서는 객체 제안을 위해 227x227로 리사이징 해야하지만 저자들은 96x96의 패치가 필요했다. 저자들은 fig 6의 구조를 채택했다. 6번째층을 변환한 Conv6층은 4096 채널을 갖고 각각의 유닛은 pool5의 3x3 region에 연결된다. 그리고 1 x 1 커널을 연결해 1024 채널로 줄인다. 그 후는 그림과 같이 FCN, softmax 연결한다. 실험 결과는 아래 표와 같다.
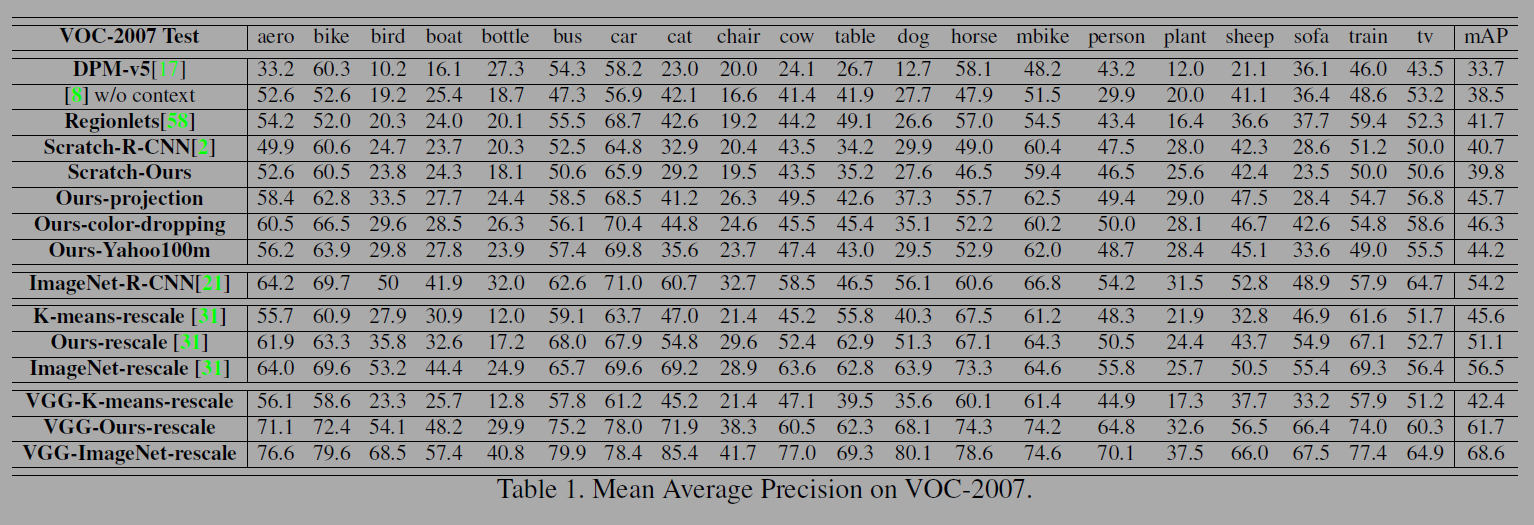
저자들의 아키텍쳐(trained from scratch)는 알렉스넷 보다 성능이 낮다. 저자들은 사전학습으로 성능을 개선해 6%의 성능개선을하고 알렉스넷보다 5%성능이 나아졌다. 그러나 이미지넷을 사전학습한 RCNN보다 8%정도 성능이 낮다. 추가적인 베이스라인을 운영했는데, 배치 놈을 사용하면 성능이 저하되었다. 다양한 데이터셋의 편차를 이해하기 위해 Yahoo/Flickr 100M 데이터셋에서 추가실험을 했다. 이미지넷과 from scratch model의 중간정도 성능이다.
결국 배치놈을 제거하고 fc와 conv층의 가중치와 편차를 평균 0 분산 1로 rescaling했다. 그리고 모든 사전학습된 fc층을 제거하고 K-means 방법으로 다시 초기화하는 방법도 사용했다(K-means-rescale).
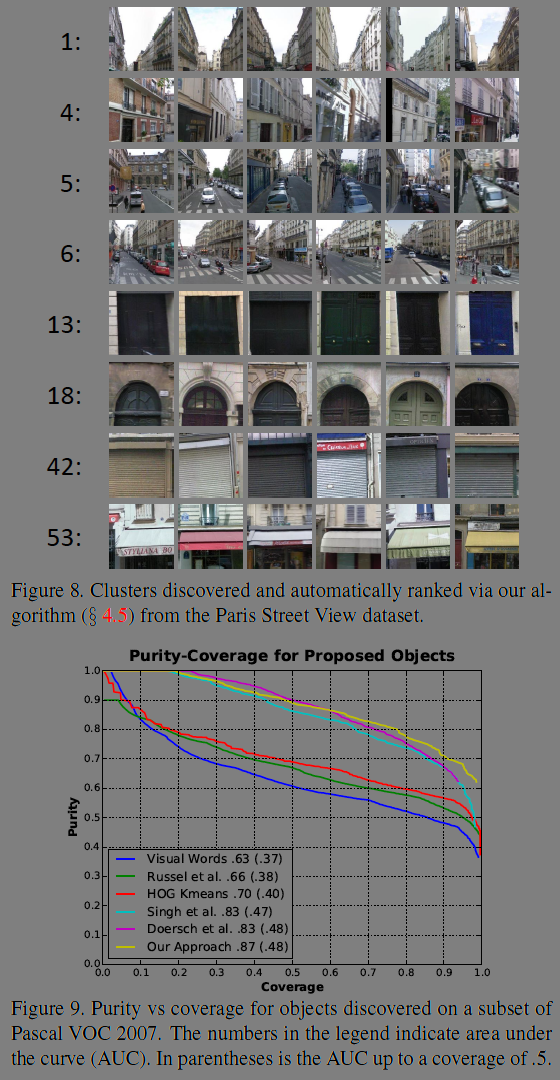
그리고 대규모의 데이터셋에서 비지도 객체 검출(visual object discovery)을 목표로하는 visual data mining 실험을 했다. 이는 같은 의미를 묘사하는 이미지 조각을 발견하는 것으로 비정형 데이터 연관 분석에 사용될 수 있다. 같은 개체에서 겹치지 않는 네장의 인접한 패치를 사용하고 공간적인 레이아웃과 상관없이 네 패치와 연관되는 상위 100개의 이미지를 찾았다. 그리고 geometric 검증을 진행해 기하학적으로 일관되지 않은 것들을 필터링 했다.

또 다른 실험도 진행했는데, VOC 2007 데이터셋에서 저자들이 개발한 알고리즘의 순도(purity), 커버리지(coverage)을 평가했다. 상대적 위치 정확도는 38.4%의 수치를 기록해 어려운 태스크이면서도 단순 기대값인 12.5%보다 높은 인간의 수준과 비슷했다.
다양한 실험을 진행했군.. 결론이 별도로 없는게 신기한 구성이긴하다.
Reference
'papers' 카테고리의 다른 글
| NICE: Non-linear Independent Component Estimation (0) | 2025.03.21 |
|---|---|
| U-Net: Convolutional Networks for Biomedical Image Segmentation (0) | 2025.02.19 |
| Fully Convolutional Networks for Semantic Segmentation (0) | 2025.02.13 |
| Distilling the Knowledge in a Neural Network (0) | 2025.01.30 |
| You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.12.18 |



