U-Net 논문이다. 논문을 정리하기 전에 대략적으로 먼저 읽어보니 FCN에서 사용한 skip connection의 개념과 upsampling의 개념을 활용하였고 매우 적은양의 바이오 의료데이터라는 데이터의 도메인을 잘 이해하고 data augmentation 전략을 잘 수립한 것이 모델의 성능을 끌어올리는데 도움이 된듯하다.
논문의 구성은 간단해 보이지만 지금 시점에서 10만회가 넘는 피인용수를 기록하고 있다.
간단해 보인다는 것은 잘 정리 되었다는 뜻! 내가 보기에도 정리되지 못한 실험과 막연한 글쓰기로 리젝당한 경험이 있기에 롤 모델로 삼고 싶은 실험과 글쓰기 사례이다.
contract path로 context를 포착하고 symmetric expanding path로 정확하게 위치를 포착한다(localization).

기존연구에서는 패치가 중복되는 슬라이딩 윈도우(sliding window)를 활용되는 것과 로컬라이제이션 성능과 맥락(context)를 활용하는 것이 상충되었다(trade-off). 패치가 클수록 max-pooling이 더 많이 필요해 로컬라이제이션 성능이 줄어들지만 패치의 크기를 작게하면 학습시에 조그마한 맥락을 파악하기 때문이다. 당시 최신 연구에서는 네트워크에 여러개의 층을 쌓음으로써 두가지 상충되는 문제를 해결하였다.
저자들은 Fully Convolutional Network(FCN) 구조를 기반으로 아키텍처를 구성하는데, 적은 수의 학습 데이터로 더 정확한 세그멘테이션(segmentation)을 하였다. 이전 연구중에는 여러개의 레이어를 활용해 contracting network를 구성하는데, 풀링을 업샘플링으로 대체하여 출력의 해상도를 향상시켰다. 로컬라이즈를 하기 위해 고해상도의 특징과 업샘플링된 출력을 결합하였다.
fig 1에 보면 흰색박스와 업샘플링된 파란 박스를 붙여놓은 박스들이 있다. U 모형에서 왼쪽은 두개의 3 x 3 콘볼루션, ReLU, 2 x 2 최대 풀링을 적용한 일반적인 CNN 모델 구조인 contracting path이고 각 단계마다 피쳐의 개수는 두배로한다. 오른쪽은 up convolution을 포함하는 expansive path이로 피쳐 채널의 크기를 반으로 하지만 contracting path를 통해 concat한다. 각 마지막 층에는 1 x 1 콘볼루션을 추가해 64층을 클래스 개수로 변환한다. 총 23개의 콘볼루션 층을 사용해 모델을 구성하였다.

그림 2에서 노란색 영역에서 로컬라이즈를 하기 위해 파란색 영역이 입력으로 필요하다(Overlap-tile strategy) . 그림 밖의 파란 영역은 미러링으로 외삽하였다(extrapolated by mirroring). 경계영역의 픽셀을 예측할때 맥락정보를 보충하는 역할을 한다. 저자들은 업샘플링 부분에 큰 채널의 피쳐를 활용해 맥락 정보가 높은 해상도의 계층으로 전파(propagete)되도록 했다. 결과적으로 U자형의 대칭적인 모습이 나타난다. 저자들의 모델은 콘볼루션층만으로 이루어져있어 segmentation 맵이 입력의 픽셀별 맥락정보를 포함한다.
저자들은 데이터 확장(data augmentation)을 위해 elastic deformation이라는 방법을 이용한다(bio쪽에서 자주 사용하는 방법인듯 하다). 이를 통해 invariance를 학습한다. 논문을 읽다보면 invariance라는 단어가 많이나오는데, 검색하기로는 입력이 달라져도 출력이 같다는 의미라고 한다. 강건성이라고 해야하나? 싶은데 배치 놈에서 배치의 평균과 표준편차를 정규화하여 균일하게 만드는 것과 일맥상통할 것이다..
세포 구분(cell segmentation) 태스크에서는 같은 클래스의 touching object를 분리하는 것이 어렵다. 세포가 다닥다닥 붙어있을 때 경계를 구분하는 것이 어렵다는 뜻인듯 하다. 저자들은 붙어있는 세포사이의 배경 레이블에 더 큰 가중치를 주는 가중손실(weighted loss)을 제안한다.
손실함수는 픽셀단위 소프트맥스와 크로스엔트로피 손실 결합한 에너지(energy) 함수를 사용한다. 픽셀이 x가 k번째 클래스에 속할 확률을 아래와 같이 계산한다. p_k값이 1이면 다른 k의 p는 0에 가깝다는 뜻이다.

아래의 함수를 통해 손실함수 함수 E의 값을 구한다. 픽셀 x의 실제 클래스와 차이점을 cross entropy로 구하는 것인데, 확률이 1에 가까울수록 손실함수가 작아진다. 소프트 맥스의 크기가 커져 확률값이 1에 가까워 질수록 손실함수의 y값은 0에 가깝게 되기 때문이다.

저자들은 ground truth segmentation 별로 가중치를 부여하고 특정 클래스에 속한 픽셀들의 빈도(frequency)를 강조하기위해 가중치 맵(weight map)을 미리 계산했다. 그리고 이는 세포들의 경계(border)를 학습하게 된다.

가중치는 아래 수식으로 계산된다. d1은 가장 가까운 셀과의 거리, d2는 두번째로 가까운 셀과의 거리이다.
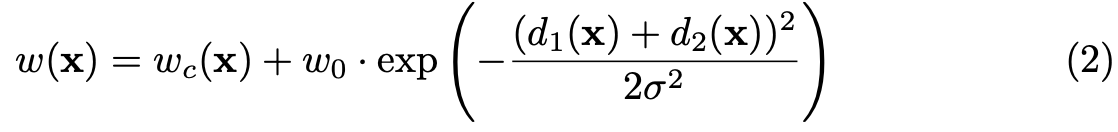
저자들은 콘볼루션을 많이 사용하고 paths를 사용했기 떄문에 가중치 초기화가 매우 중요하고 강조한다. 그렇지 않으면 특정 뉴론만 과하게 활성화 되기 때문이다. 이상적으로는 단위 분산(unit variance)를 가지도록 피쳐맵을 설정해야한다고 한다. 저자들은 2/N^1/2의 표준편차를 가진 정규분포를 바탕으로 초기화했다.
그리고 연구진에게 데이터 수가 적었기 때문에, 회전, 이동, 변형, 명암 변화에도 학습의 강건성을 위해 데이터를 증강했다. 변위벡터 생성, 픽셀단위 변위 계산(bicubic interpolation), 드랍아웃 저자들의 방법은 세가지 segmenation 태스크에서 효과적인 IoU를 기록하며 1등을 기록했다. 실험 결과는 논문 원문 참조.
Reference
https://arxiv.org/pdf/1505.04597
'papers' 카테고리의 다른 글
| Fully Convolutional Networks for Semantic Segmentation (0) | 2025.02.13 |
|---|---|
| Distilling the Knowledge in a Neural Network (0) | 2025.01.30 |
| You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.12.18 |
| Deep Residual Learning for Image Recognition (0) | 2024.12.10 |
| Learning Deep Features for Discriminative Localization (1) | 2024.11.30 |



