YOLO 모델은 네이버에서 인턴하던 19.12월 - 20.2월 사이에 당시 연구원들이 많이 보고 활용하고 있던걸로 기억하는 모델이다.
도입부에서 저자는 YOLO 모델은 사람이 시각적으로 빠르고 정확하게 여러가지 일을 한다는 점에 착안하였다고 한다.
이미지에서 객체가 어디에 있는지, 어떤 클래스의 객체인지 판별하는 모델중 동영상과 같은 real-time 분류가 가능한 속도의 모델이다. 초당 45개의 이미지 처리가 가능하고 작은 크기의 모델인 Fast YOLO는 초당 155 프레임의 처리가 가능하다.
YOLO detection 모델은 (1) 이미지를 리사이징하고 (2) 컨볼루션 네트워크를 거쳐 (3) 모델의 신뢰도를 따라 계값을 설정한다.

당시에 비슷한 역할의 모델로는 전체 이미지를 나눠서 작동하는 슬라이딩 윈도우 접근법인 deformable parts models(DPM, 딥러닝 이전 기법)과 잠재적인 bounding box(BB)를 제안하고 region proposal 방법을 사용하는 R-CNN 모델이 있다. 이러한 모델들은 느리고 각각의 컴포넌트를 따로 학습해야하는 이유로 최적화가 어렵다.
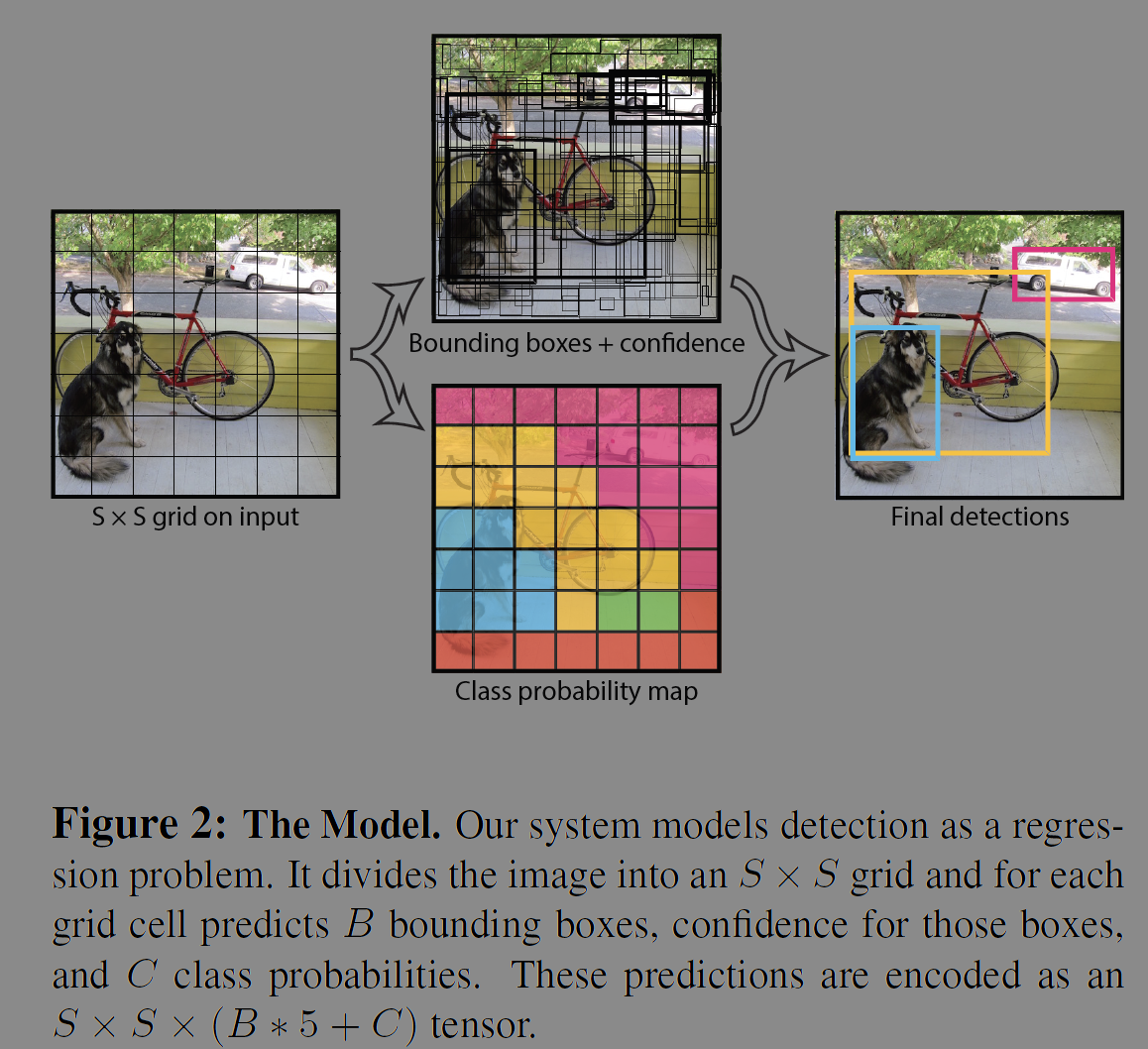
저자들은 객체 탐지(object detection)을 이미지 픽셀에서 bounding box와 클래스의 확률까지 단일 회귀 문제(single regression)로 재구성하였다. 한번 보면 객체가 무엇인지 어디에 있는지 알 수 있다는 의미에서 논문 제목을 지었다. 하나의 CNN에서 동시에 여러개의 BB와 클래스의 확률을 예상한다. 이 통합된 모델은 기존 객체탐지 방법에 비해 여러 이점이 있다.
우선 매우 빠르다. 단일 회귀방식이기 때문에 여러 파이프라인이 필요하지 않다. 테스트시에 객체탐지를 위해 뉴럴넷을 돌리기만 하면 된다. 저자들의 기본 모델은 초당 45프레임의 이미지를, fast 버전은 150프레임 이상을 처리할 수 있다(Titan X GPU without batch processing). 당시 기준으로 다른 모델보다 두배이상의 mAP를 달성했다.
두번째로 이미지 전체를 기반으로 추론한다. 슬라이딩 윈도우나 지역 추천방법과 다르게 학습과 추론시에 클래스와 외관에 대한 문맥적인 정보를 인코드(encode)한다. 예컨데 Fast R-CNN은 문맥 이해능력이 약해서 객체의 배경 조각에 대해서는 실수한다. YOLO는 반절의 에러율을 보인다.
세번째로 YOLO는 객체의 일반화 가능한 표현(representation)을 학습한다. 보통 이미지에서 모델을 학습하고 미술품에서 추론했을때도 YOLO는 DPM이나 R-CNN 같은 모델보다 좋은 성능을 보인다. 새로운 도메인이나 예상치 못한 입력에 효과적이라는 의미이다.
저자들은 이 연구를 통해 객체 탐지의 프로세스를 단일 신경망으로 통합했다. 개발한 모델은 전체이미지에서 모든 클래스에 대해 각각의 BB를 동시에 예측한다. YOLO는 end-to-end로 학습하여 실시간의 속도로 꽤나 좋은 성능을 내는 것이다. 우선 이미지를 S x S 그리드로 분할한다. 만약에 객체의 중심이 특정 그리드 셀에 포함되면 그 그리드 셀은 객체 탐지에 책임이 있다. 분할된 그리드 셀은 BB, 신뢰도(confidence score)를 예측한다. 신뢰도는 모델이 얼마나 정확하게 박스에 객체를 담고 있는지에 대한 점수이다. 셀 안에 객체가 없으면 0점이고 있으면 예측값과 정답값의 IOU(intersection over union)로 정해진다.

BB는 x, y, w, h, confidence를 포함한다. (x, y)는 그리드 셀의 중심 좌표를 뜻하고 w, h는 전체 이미지를 기준으로 예측된다. 각 그리드 셀은 객체에 대한 클래스의 조건부 확률을 예측한다.
위의 수식을 조금 더 풀어 쓰면 아래와 같다.

네트워크 디자인은 다음과 같다. 초기 콘볼루션 층은 이미지에서 특징을 추출하고 FCL(fully connected layer)는 좌표와 확률을 출력한다. 저자들의 모델은 이미지 분류를 위한 GoogLeNet에서 영감을 받았다. 24개의 콘볼루션층과 2개의 FCN으로 구성된다. 인셉션 모듈 대신 1 x 1 reduction layer를 사용했다. 빠른 버전의 YOLO도 디자인 했는데, 9개의 콘볼루션과 적은 필터를 사용했고 다른 파라미터들은 같다.

저자들은 ImageNet 1000클래스 대회 데이터셋으로 20개의 콘볼루션 층을 이용해 사전학습(pretrain)시켰다. 학습에는 대략 1주가 걸렸고 top5 정확도는 88%이다 ImageNet 2012 셋에서. 저자들은 사전학습한 모델을 탐지를 위한 모델로 바꿨다. 4개의 콘볼루션과 2개의 FCN층을 랜덤하게 초기화시켜 덧붙였다. 마지막 층은 클래스 확률과 BB의 좌표를 예측한다. 저자들은 BB의 포과 높이를 정규화 하기 위해 0과 1사이의 값으로 변경했다. 그리고 BB의 x, y 좌표를 특정 그리드셀의 0과 1사이의 값인 오프셋으로 파라미터화 했다.
마지막 층과 다른 층들은 아래 그림의 leaky rectified linear activation을 사용했다.

저자들은 sum-squared error를 최적화했다. 이는 평균 정확도를 최대화하지는 못하지만 최적화가 쉽다. 이 방식은 localization 에러와 classification 에러를 동등하게 바라보는데, 이상적인 방법은 아닌듯 하다. 어떤 그리드 셀은 객체가 아예 없기도해서 confidence 점수가 0으로 되어 셀의 기울기가 너무 커져 모델 학습이 불안정하게 되기도 한다. 저자들은 이를 방지하기 위해 BB좌표 예측하는데 사용하는 로스를 키우고 객체가 없는 박스들의 confidence에서 발생하는 로스의 영향을 감소시켰다(아래 그림의 값 사용).

Sum-squared error는 큰 B나 작은 B나 동등하게 가중치를 부여한다. 에러 지표에 큰 B의 작은 움직임이 작은 박스의 움직임보다 더 영향을 줄 수 있는 것이다. 저자들은 이를 해결하기 위해 BB의 높이와 너비를 실제 값이 아닌 제곱을 취하여 계산했다.
YOLO는 그리드 셀마다 여러개의 BB를 예측할 수 있다. 학습시에는 어떤 예측치가 가장 높은 IoU를 갖고있는지를 통해 하나의 박스가 하나의 객체만 책임지도록 의도했다.

비용함수는 객체가 그리드에 있을 때 분류 에러에 페널티를 준다. 그리고 BB 좌표 에러도 IOU가 가장 높은경우에 페널티를 준다. 저자들은 PASCAL VOC 2007, 2012데이터셋에서 135 에폭 학습시켰다. 배치크기는 64, 모멘텀은 0.9 0.0005의decay를 이용했다.
YOLO 모델은 테스트 이미지로 추론할때 다른 분류기 기반 모델들에 비해 압도적으로 빠르다. 그리드 방식의 설계는 이미지의 여러 지역에 BB를 감지할 수 있다. 종종 큰 객체나 여러 셀의 경계에 걸치는 경우에도 잘 localize 된다.
YOLO 모델은 각각 그리드 셀이 두개의 BB를 예측해도 하나의 클래스만 가질 수 있다. 이러한 지역적인 한계는 새 떼처럼 작은 여러 객체들이 몰려있는 경우에 한계를 지닌다. 새로운 양상의 비율이나 구성에 대한 일반화도 어렵고 YOLO 모델은 다운샘플 층을 여러개 거치기 때문에 상대적인 피쳐(relatively coarse features)를 사용한다. 작은 객체의 작은 에러가 큰객체의 작은 에러보다 더 중요하게 다뤄진다.
저자들은 다른 Real-time system들과 비교실험했다. 아래 실험결과를 보면 YOLO 모델은 꽤나 괜찮은 mAP결과를 실시간에 가까운 30 fps 이상에서 사용할 수 있다(fast 모델은 155fps with 52.7mAP). Fast R-CNN모델만 봐도 2초 당 1개 꼴로 추론가능하다.

VOC 2007 에러 분석을 통해 YOLO 모델과 다른 SOTA detector들과 차이점을 비교했다. IOU를 기준으로 0.5 이상이면 correct, 0.1에서 0.5 사이이면 localization, similar는 0.1보다 큰 경우라고 예측했다. 0.1 보다 작다면 background: false positive한 경우, other는 예측한 클래스가 틀린경우로 IoU가 0.1보다 큰 경우이다.

Table 3은 20개의 클래스에 대해 클래스별 AP 결과이다.

저자들은 미술품에 있는 사람을 탐지하는 실험(person detection in artwork)를 통해 일반화 성능에 대한 실험도 진행했다. Figure 5를 보면 다른 모델들의 경우에 VOC 2007에서 AP가 높아도 Picasso데이터 셋에서는 AP나 F1이 낮다.

그리고 realtime application에 적용 가능함을 실험하고 프로젝트 웹사이트를 통해 결과를 공개하고 있다.

'papers' 카테고리의 다른 글
| Fully Convolutional Networks for Semantic Segmentation (0) | 2025.02.13 |
|---|---|
| Distilling the Knowledge in a Neural Network (0) | 2025.01.30 |
| Deep Residual Learning for Image Recognition (0) | 2024.12.10 |
| Learning Deep Features for Discriminative Localization (1) | 2024.11.30 |
| XGBoost: A Scalable Tree Boosting System (3) | 2024.11.07 |



