XGBoost 논문에 대한 리뷰이다. 논문 공부는 원문 읽기와 Youtube 영상, ChatGPT와의 질의응답으로 커버가 되는 듯하다. 이번 글에서는 논문의 2장에 해당하는 알고리즘 부분에 집중해서 리뷰할 예정이다. 완벽히 이해는 못한 상태라 우선 글로 적고 나중에 채워나가려 한다.
저자들은 이 연구의 기여에 대해 4가지로 강조한다. 단순히 알고리즘만 제안한 것이 아니라 하드웨어 차원에서 최적화를 수행하는 방안(cache-aware block structure)을 제시하였다.
- We design and build a highly scalable end-to-end tree boosting system.
- We propose a theoretically justified weighted quantile sketch for efficient proposal calculation.
- We introduce a novel sparsity-aware algorithm for parallel tree learning.
- We propose an effective cache-aware block structure for out-of-core tree learning.
2장 TREE BOOSTING IN A NUTSHELL에서는 알고리즘에 대해 설명한다. 수식과 부스팅 방법에 대한 이해가 필요하다.
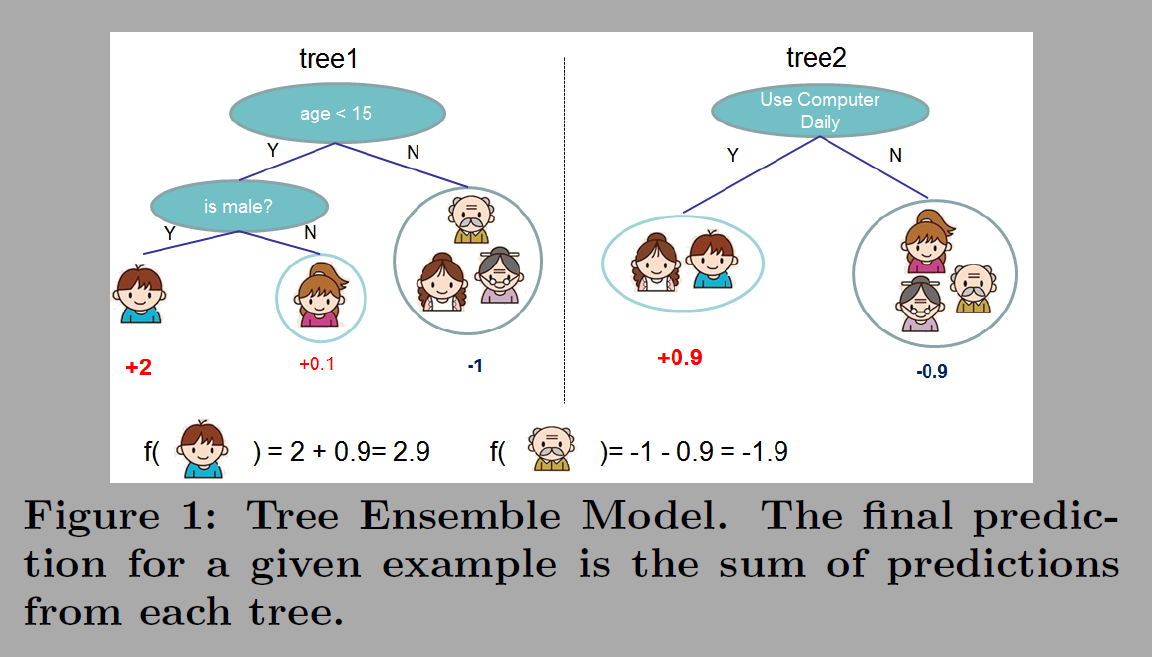
최종 예측 값 Y^(phi)는 앙상블 모델(ensemble model)을 구성하는 트리의 합(K additive functions)이다. f(x)는 트리 k가 입력 xi에 대해 예측한 값이다. 두번째 그림에서 보면 파란옷 어린이가 입력되면 트리1, 트리2에서 예측 값을 더해 2.9가 되고 할아버지의 경우 예측 값이 -1.9가 된다.
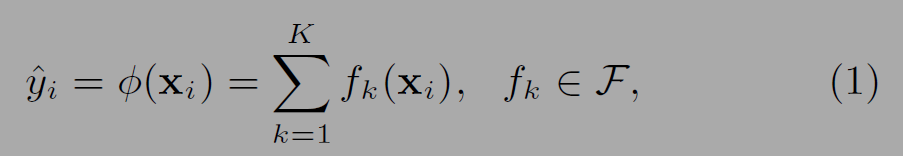
f(x)의 수식은 아래와 같다.
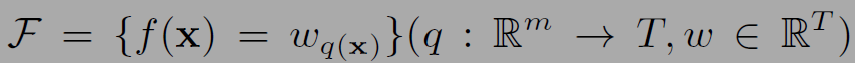
(1)식의 트리 함수의 집합을 학습하기 위해 (2)의 loss식의 목적함수를 학습한다. 함수 l은 defferentiable convex loss function으로 예측과 타겟의 차이를 측정한다. 뒤의 오메가는 모델의 복잡도를 제한하는 정규화 텀으로 오버피팅을 방지하는 역할을 한다. 리프노드의 수(T)에 비례한다. 두번째 텀은 가중치에 대한 L2 정규화 항이다.
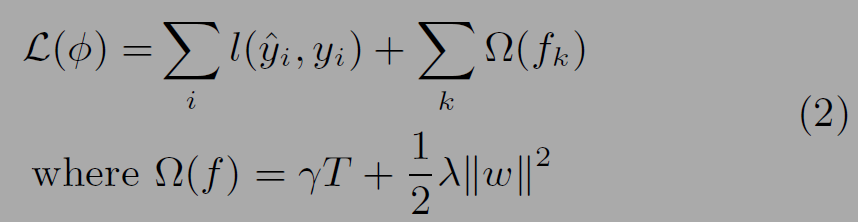
결국 모델 학습은 로스를 최적화(최소화)하는 방향으로 이뤄지는데, 가중치(w)가 커질 수록 loss의 값이 커지게 된다. 즉 이 모델에서는 w값이 너무 커지지 않으면서도 L함수가 작아지도록 학습하는 것이 목표이다. 특정 가중치가 너무 커지면 과적합 위험이 있기 때문이다. GTB알고리즘은 트리를 추가하면서 학습이 되는데, 아래 수식부터 등장하는 t는 t번째로 학습하는 것을 의미한다.

위의 수식을 통해서는 Loss를 계산하는 방식이 greedy함을 알 수 있다. 첫 번째 텀에서 손실(loss)의 비교를 t-1단계의 예측값과 i시점의 추가된 트리의 값(함수 f)을 더하는 방식으로(additive manner) 구한다. 잔차학습을 의미한다.

2계 도함수(second order approximation)은 목적함수를 빠르게 최적화하기 위해 사용된다.
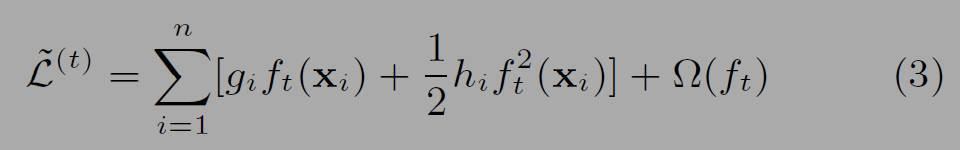
g_i와 h_i는 손실함수의 일계, 이계 도함수(first and second order gradient statistics)이다. 수식 (3)에서는 상수항인 l텀이 목적함수를 단순화하려는 의도로 제거하였다.
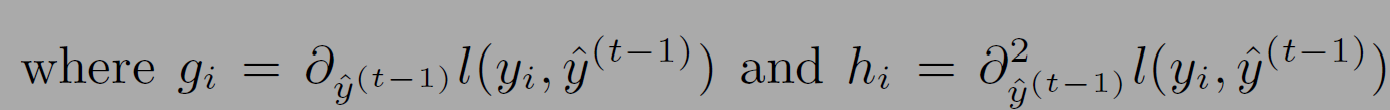
(4)의 아래식에서는 리프(T : # of leafs) 별로 그 리프를 기준으로 수식을 정리하였다. 위의 식을 보면 sigma에 i=1부터 n까지 모든 데이터를 순회하고 아래를 보면 리프를 기준으로 (T) I에 속하는 i들의 값을 더한다.
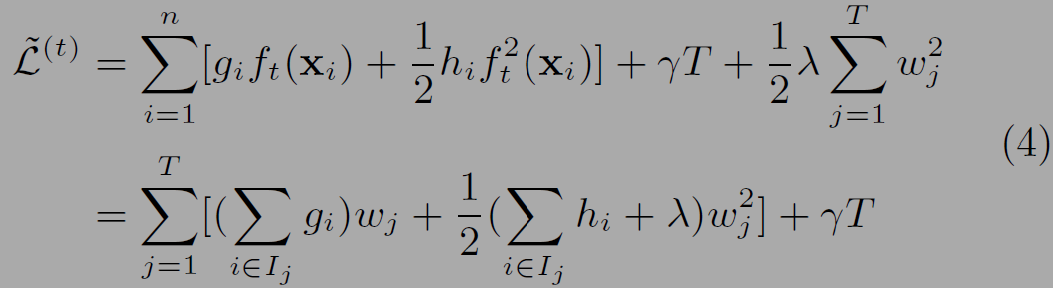
(4)식에서는 새로운 트리 t를 계산하는 것과 관련 없는 상수항인 l텀을 제거하였다. (5)의 식에서는 가중치를 구한다. 부스팅 모델에서는 가중치를 통해 새로 더해지는 트리가 오차를 보정하는 정도를 조절할 수 있다.

(6)은 트리 구조(q)에 대한 품질평가에 사용되는 식이다.
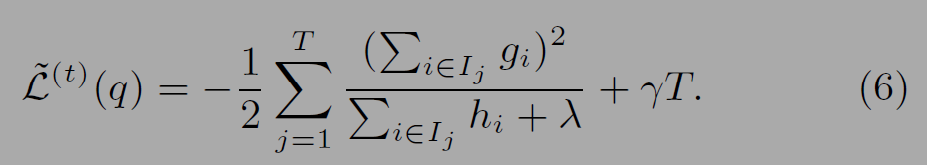
아래 수식 (7)을 통해서는 좌우 분할이 얼마나 Loss를 낮추는지를 계산한다. 논문 3장에서는 최적의 Split을 찾기 위한 연구도 진행했다. Algorithm1은 모든 스플릿을 확인(greedy)하는 것이다. 가능한 모든 분기를 계산하기 때문에 효율적이지 않고 메모리에 데이터를 한번에 다 올려야하는 단점이 있다. Algorithm2는 approximate 방법을 사용한다. percentile에 따라 분기점을 일부만 설정하고 계산한다. Algorithm3은 sparsity aware(missing values제외)를 통해서 최적화된 분기를 찾는다.
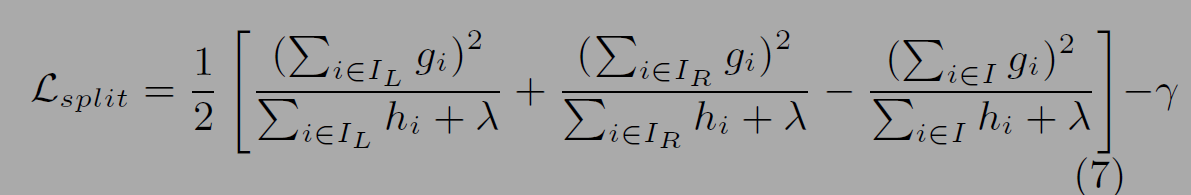


논문에서는 알고리즘 뿐 아니라 하드웨어 최적화까지 설명하고 있으므로 한번쯤 훑어보면 좋다.
ChatGPT없으면 논문공부 어떻게하나 싶다.
REFERENCE
https://youtu.be/VkaZXGknN3g?si=cHIpHsA9_DjuI3jt
https://youtu.be/VHky3d_qZ_E?si=XdLmejQQWilDAM8M
ChatGPT
https://arxiv.org/abs/1603.02754
'papers > Deep learning' 카테고리의 다른 글
| NICE: Non-linear Independent Component Estimation (0) | 2025.03.21 |
|---|---|
| Distilling the Knowledge in a Neural Network (0) | 2025.01.30 |
| ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION (3) | 2024.10.16 |
| Layer normalization (2) | 2024.09.17 |
| Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (0) | 2023.09.16 |



