이 논문 2015년 작성되었고 24년 11월 기준 12,000회가 넘는 인용을 기록하고 있다. Class Activation Mapping(CAM)으로 유명한 연구이고 CNN모델의 마지막 Fully connected layer를 제외한 컨볼루션에 Global Average Pooling(GAP)을 적용해 localization에 성과를 내었다.
저자들은 다양한 태스크의 실험을 했다.
CNN모델은 localization에 강점이 있는데, 컨볼루션 층 다음 마지막 층에 분류를 위한 FCL가 연결되면 이 능력을 상실한다. 이를 유지하기 위해 FCL을 제거하고 GAP를 사용하는데, 이는 원래 오버피팅을 방지하기 위한 방법이다. 연구진은 이 네트워크가 regularizer 역할뿐 아니라 localization 능력을 보유할 수 있음을 발견했다. 심지어 모델의 원래 학습 목적(분류)이 아님에도 단번의 순전파 학습으로도 이미지에서 지역(region)을 확인할 수 있다.
그림1은 객체 분류 모델이지만 사람과 상호작용하는 물체(그림에서는 칫솔, 톱)를 구분한다. 모델의 구조는 단순해도 ILSVRC 벤치마크의 weakly supervised object localization에서 37.1%의 top5에러로 1등인 AlexNet과 거의 비슷했다.

이 연구에서는 CNN모델에 Global average pooling을 사용한 Class activation mapping을 제안한다. 저자들은 GoogLeNet, Network in Network 모델과 유사한 아키텍쳐를 사용했다. 마지막 출력 앞 피쳐맵에 GAP를 붙이고 이를 FCN에 연결시켜 분류했다. 출력층의 가중치를 사영하여(projecting back) CAM을 생성한다. 이미지 분류에 활성화된 영역을 알 수 있다. CNN모델 학습이 블랙박스가 아닌 이미지의 어떤 부분에 집중하는지 알 수 있는 것이다.
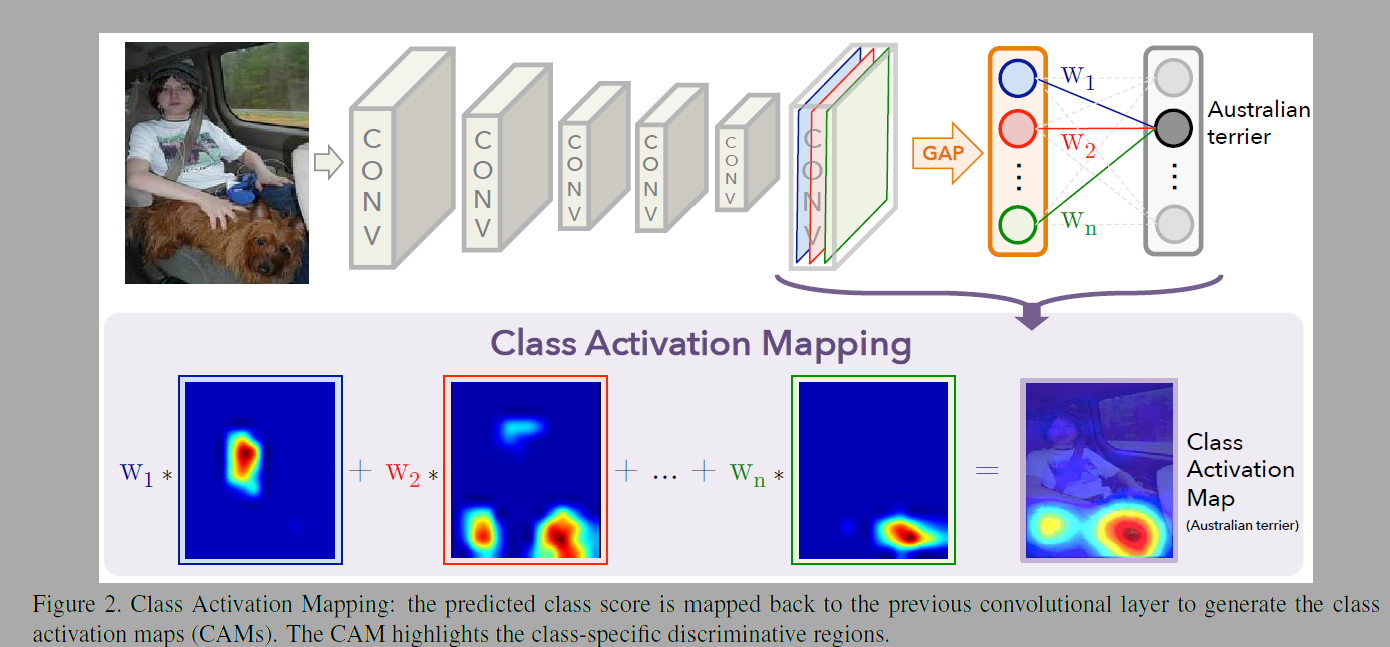
수식 (1), (2)는 그림 2의 GAP를 계산하는 식이다. k는 피쳐 맵의 순서(index), x, y는 좌표, (x, y)는 특정 위치에서 활성화 값이다. GAP로 해당 순서의 필터에 대한 중요도를 구하고 가중치를 곱한것들을 더하면 각 클래스에 대한 점수를 계산한다 (S_c) . M_c는 클래스 활성화 맵(CAM)으로 분류하는데 있어 클래스 c에 대한 좌표(x, y)의 중요도를 나타낸다.
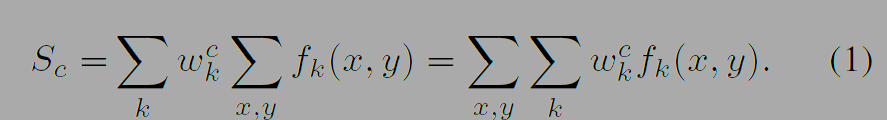

CAM을 입력 이미지 크기로로 업샘플링하면 특정 클래스에 대해 관련있는 부분을 확인할 수 있다. (일반적인 CNN은 다운 스트라이드나 풀링같은 샘플링을한다). 그림 4를 보면 활성화된 부분과 원본 이미지의 크기가 같다. 활성화된 부분을 통해 클래스 c와 관련된 이미지의 중요한 영역을 알 수 있다.

Global average pooling(GAP)와 Global max pooling(GMP)를 비교해보자.
GAP는 물체의 범위를 확인하는데 GMP보다 낫다. 왜냐하면 맵의 평균을 취할때 값은 모든 구분되는 부분 (discriminative part) 을 찾으면서 출력을 최대화 할 수 있다. 활성도가 낮은 부분은 최종 출력의 값을 낮추기 때문에 구별되는 부분에 높은 활성화 값을 높이도록 학습하는 것이다. GMP는 활성화가 낮은 포인트들은 제외되고 가장 구분되는 부분만 집중한다.

마지막 fcl를 제거하면 네트워크의 파라미터를 많이 줄일 수 있다.(vggnet 90%) 콘볼루션의 마지막 피쳐의 해상도를 크게하면 localization 성능이 좋아진다. 이를위해 저자들은 실험할때 각 모델의 이전층들을 제거하기도함. (분류성능은 저하된다)
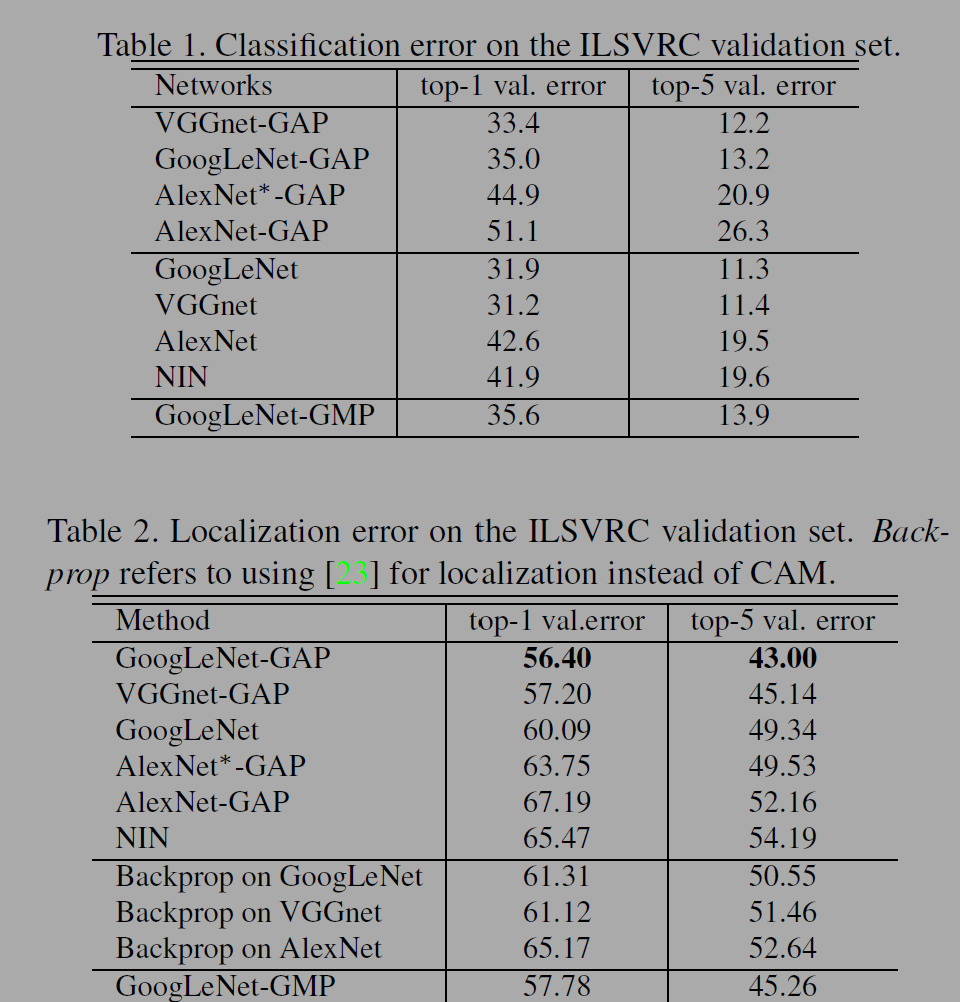
table1을 보면 GAP를 적용한 모델은 기본 모델에 비해 1-2%정도씩 에러율이 떨어진다. table2에서는 GAP를 적용한 모델에서 localization 에러가 크게 향상됨을 알 수 있다. GoogLeNet-GAP와 GoogLeNet-GMP 비교하면 GAP모델이 객체의 범위를 확인(localization)하는데 성능이 낫다.

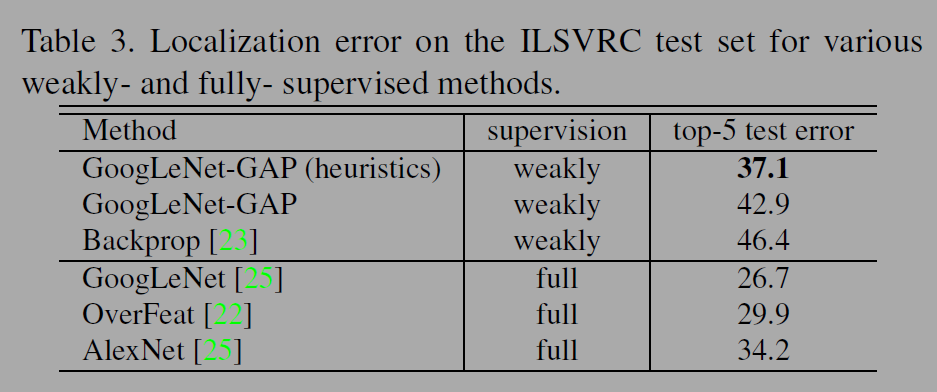
다음으로는 CAM을 기반으로 다른 크기의 바운딩 박스(bounding box)를 생성하는 휴리스틱을 이용 분류 정확도와 localization 정확도의 trade-off를 실험했다. top1, 2 객체와 딱 맞는 타이트한 박스, 여유가 있는 loose박스 하나씩 고르고 top3는 loose 박스만 선택한다. loose box는 좀더 큰 맥락을 포함하기 때문에 분류 성능향상에 도움이되고 tight box는 정확한 위치 파악에 도움이 된다. GoogLeNet-GAP with 휴리스틱은 fully supervised AlexNet의 34.2%와 에러율이 거의 비슷하다. 그러나 객체의 정확한 위치를 제공하는 annotation을 보유한 full 방식(26.7%)에 비해서는 성능이 낮다.
연구진은 깊은 피쳐(Deep Features)의 일반적인 localization도 실험했다.
CNN의 깊은 층은(예컨데, AlexNet의 6,7층) 매우 효과적으로 범용적인 특징을 갖고있다. (SOTA달성) 저자들의 GAP CNN도 범용적인 특징을 잘 추출하고 특정 태스크를 위해 학습되지 않아도 범주의 영역을 잘 구분해낸다. 원래의 softmax역할을 선형 SVM으로 변경했다. Scene과 객체 분류 벤치마크 실험을했다(tbl 5).

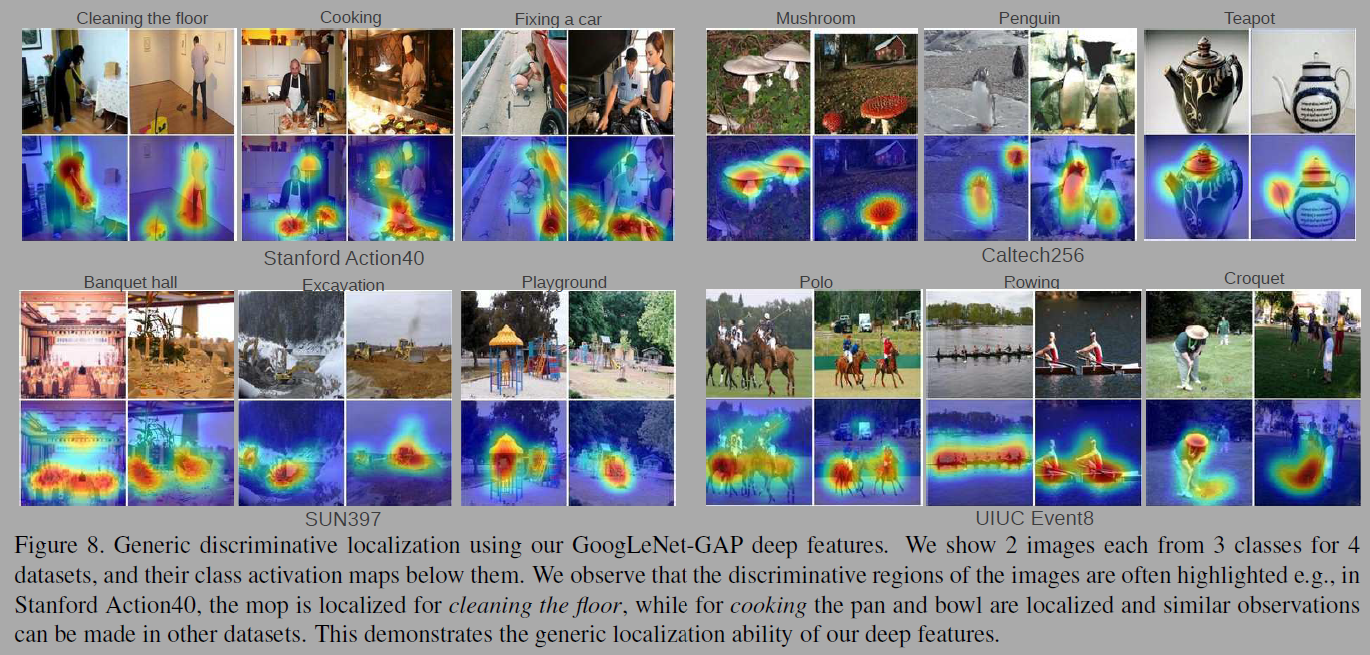
GoogLeNet-GAP와 GoogLeNet의 성능이 AlexNet보다 낫다. GoogLeNet-GAP는 generic visual features에서 거의 SOTA의 성능을 보인다. 저자는 다양한 데이터셋에서 GooLeNet-GAP과 CAM이 localization map을 생성하는지 실험한다(그림 8).
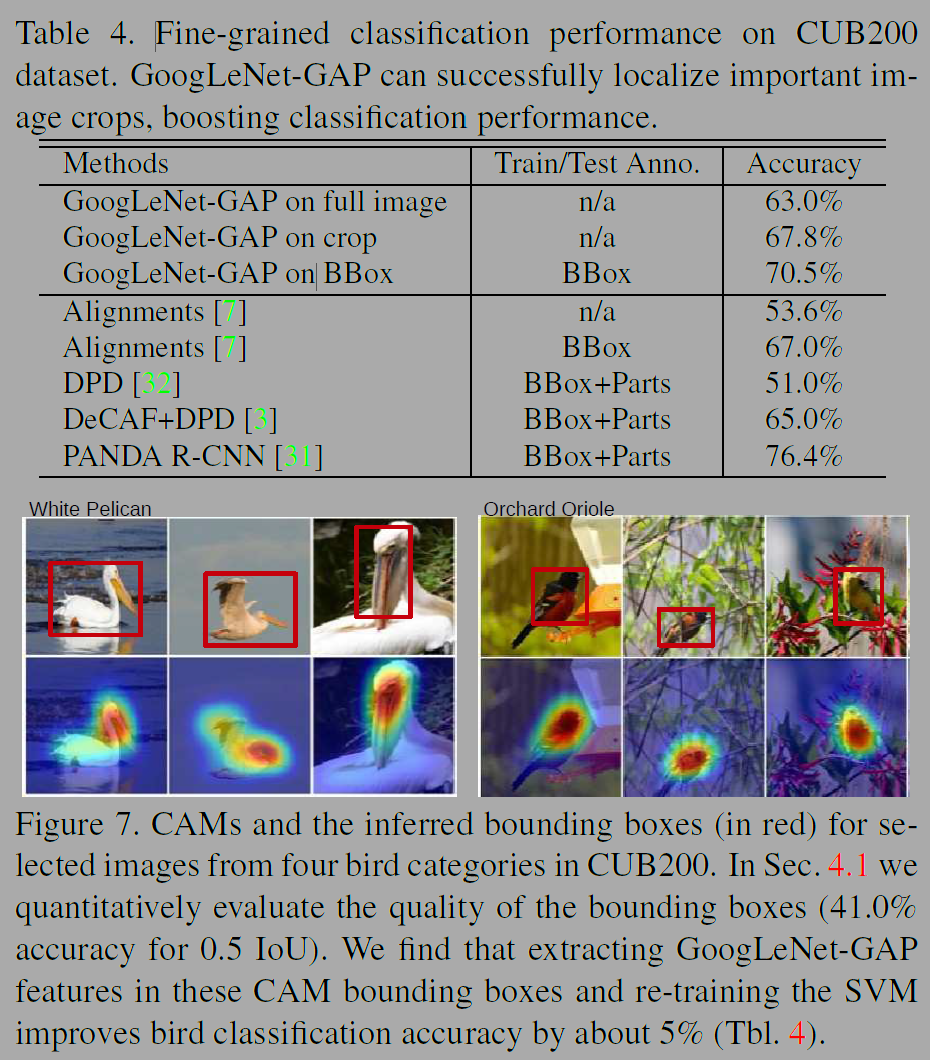
세분화된 객체(fine-grained)를 인식하는 실험도 진행하였다. Fine-grained 인식에는 우선 bounding box로 드랍하고 그 안에서 객체를 인식하는 것이 성능이 좋았다. GoogLeNet-GAP는 0.5 IoU (Intersection over Union) 기준에서 41퍼센트로 새를 localize했다.
저자는 세가지 연구를 통해 저자들의 방법이 이미지들에 있는 객체에서 고차원적인 개념의 패턴을 발견할 수 있는지도 실험했다.
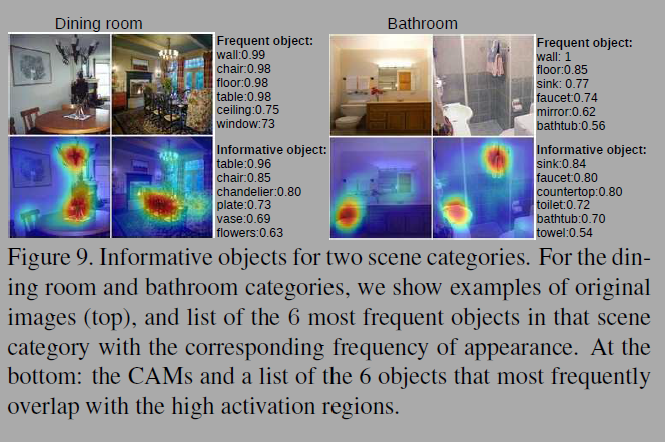
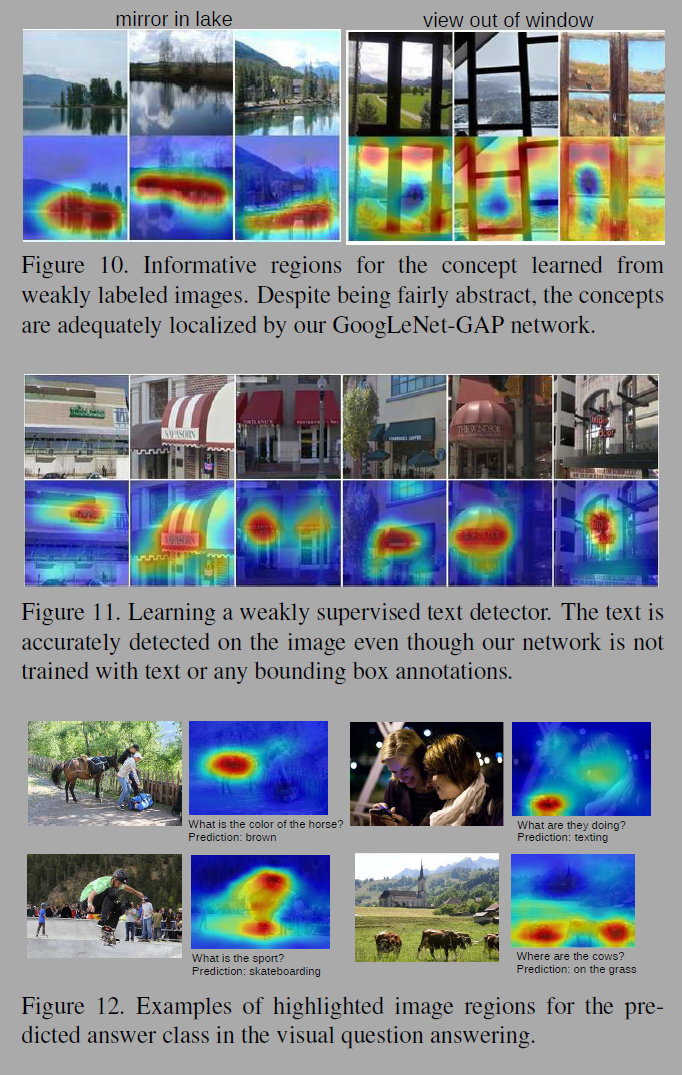
Discovering informative objects in the scenes에서는 특정 객체를 통해 장면의 카테고리를 구별한다는 것을 시사한다(fig 9). Concept localization in weakly labeled images에서는 hard-negative mining과 CAM을 결합해 이미지에서 컨셉을 추출해 시각화한다(fig 10). 추상적인 개념도 시각화 하였다. Weakly supervised text detector에서는 bounding box나 텍스트 학습없이도 이미지에서 텍스트를 감지한다(fig 11). Interpreting visual question answering에서는 이미지에서 prediction과 관련된 부분이 활성화된다(fig 12).
컨볼루션은 시각적인 개념(visual concept)을 찾을 수 있다. 낮은 층에서는 질감이나 물질을, 깊은 층에서는 객체나 풍경을 감지하여 층이 깊어질수록 더 구별적임(discriminative)를 알 수 있다. FCL(fully connected layer)에서는 다른 유닛(units)이 범주를 파악하는데 있어 얼마나 중요한지 아는 것이 어렵다. GAP과 소프트맥스 가중치를 이용하면 주어진 클래스를 구분하는데 가장 중요한지를 알 수 있다. 저자들은 이를 CNN의 class-specific units 이라고 한다. 모델의 해석가능성(interpretability)을 보여준다. 그림 13에서는 이를 실험한다.

CNN 모델의 해석가능성을 밝히기 위해 CAM 시각화를 이용해 다양한 태스크의 실험을 했다. 모델의 층이 깊어질수록 더 개념적이고 넓은 의미를 이미지에서 발견할 수 있다.
나의 소감: 실험을 위해 참 다양한 실험을 해야하는구나...!
Reference
ChatGPT
https://arxiv.org/abs/1512.04150
'papers' 카테고리의 다른 글
| You Only Look Once: Unified, Real-Time Object Detection (0) | 2024.12.18 |
|---|---|
| Deep Residual Learning for Image Recognition (0) | 2024.12.10 |
| XGBoost: A Scalable Tree Boosting System (3) | 2024.11.07 |
| ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION (3) | 2024.10.16 |
| Layer normalization (2) | 2024.09.17 |



