이 논문은 2015년 ICLR에 발표된 연구이다. 딥러닝 Loss function 최적화 알고리즘의 정석으로 자리잡은 Adam 옵티마이저에 대한 논문이다.
Adam 알고리즘은 lower-order 모멘텀 바탕의 adaptive 측정을 기본으로한 일계도함수(first-order gradient-based optimization)를 활용한 확률적 목적함수 최적화이다. 기울기의 diagonal rescaling에 불변하고 데이터나 파라미터가 커도 잘 적용된다. 논문을 이미 한번 읽은 상황이긴해도 diagonal rescaling에 불변하다는 것이 무슨 의미인지 이해가 잘 안가 chatgpt에게 물어봤다. 결과적으로는 서로 다른 가중치를 알고리즘이 보정한다는 것이다. 그리고 Adam은 온라인 학습같이 시간에 따라 변하는 non-stationery 데이터에 대해서도 잘 적용된다.
===============================================================================
Adam 논문에서 언급하는 **"Invariant to Diagonal Rescaling"**은, Adam 알고리즘이 매개변수의 스케일에 영향을 받지 않는다는 것을 의미합니다. 즉, 각 매개변수의 크기(스케일)에 따라 그라디언트가 조정되더라도, 알고리즘이 제대로 작동한다는 뜻입니다.
이를 좀 더 자세히 설명하면, 많은 최적화 알고리즘은 각 매개변수에 따라 그라디언트의 크기가 다르게 나타날 수 있습니다. 예를 들어, 어떤 매개변수는 매우 큰 값을 가질 수 있고, 다른 매개변수는 매우 작은 값을 가질 수 있습니다. 만약 이 차이를 고려하지 않고 동일하게 그라디언트를 업데이트하면, 큰 매개변수는 너무 작은 변화만 생기고, 작은 매개변수는 너무 큰 변화가 발생할 수 있습니다. 이러한 상황을 스케일 문제라고 합니다.
Adam은 각 매개변수마다 그라디언트를 따로 조정합니다. 이는 각 매개변수의 **1차 모멘트(평균)**와 **2차 모멘트(분산)**를 추적하여 업데이트 시에 그라디언트의 크기 차이를 자동으로 보정하는 방식입니다. 이 과정에서 매개변수의 크기나 스케일이 서로 달라도 적절히 조정되기 때문에, 스케일에 독립적인(invariant) 성질을 갖게 됩니다.
결론적으로, "Invariant to Diagonal Rescaling"이란 각 매개변수에 따라 다른 스케일의 그라디언트를 업데이트할 때, 그 크기 차이에 영향을 받지 않고 알고리즘이 안정적으로 작동한다는 것을 의미합니다. 이 덕분에 Adam은 다양한 문제에서 효과적으로 사용될 수 있습니다.
================================================================================
Adam은 AdaGrad, RMSProp에서 영감을 받은 알고리즘이다.
Adam은 기울기의 평균(first moments)과 분산(secend moments)를 통해 다른 매개변수를 위한 각각의 adaptive learning rate을 구한다. 아래 그림을 보면 m, v(2차 모멘트, 기울기의 제곱)의 이동평균(exponential moving average)을 갱신하는 과정과 초기 편향을 보정하는 과정도 나타나있다. 수식의 마지막을 보면 기울기의 가중평균을 기울기의 크기(제곱근을 취하므로 크기만 남음)로 나눈 값에 learning rate를 곱한 값을 더해 매개변수를 갱신한다.

$m^t/\sqrt{v^t}$는 SNR(Signal-to-noise Ratio)라고 하는데 SNR작으면 불명확성이 커진다고 판단하여 stepsize는 0에 가까워진다. 최적지점(optimum)에 가까워질 수록 SNR은 0에 가까워진다. 기울기의 그래프를 상상해보면 코스트 함수의 최적지점 근처에서는 기울기가 -, +를 왔다갔다 하는 것을 알 수 있다. SNR 수식을 보면 효율적인 stepsize t는 기울기의 scale과는 무관한 것을 알 수 있다. 위 그림과 아래 그림의 vt를 구하는 수식은 결국같다고 한다. (위는 재귀적으로 구하는 방식)
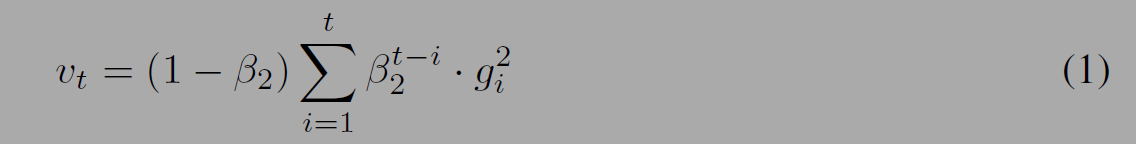
Algorithm 1의 v를 구하는 방식은 v_0이 0이기 때문에 초기편향 문제가 있어 수정된 위의 수식을 사용한다. 두 수식은 2 moment를 구하는 목적으로 같지만 편향이 수정되므로 더 정확하게 추정이 가능하다.
실험은 MNIST 데이터셋과 IMDB BoW데이터 셋을 통해 이미지, 자연어처리에서 옵티마이저를 비교했다.
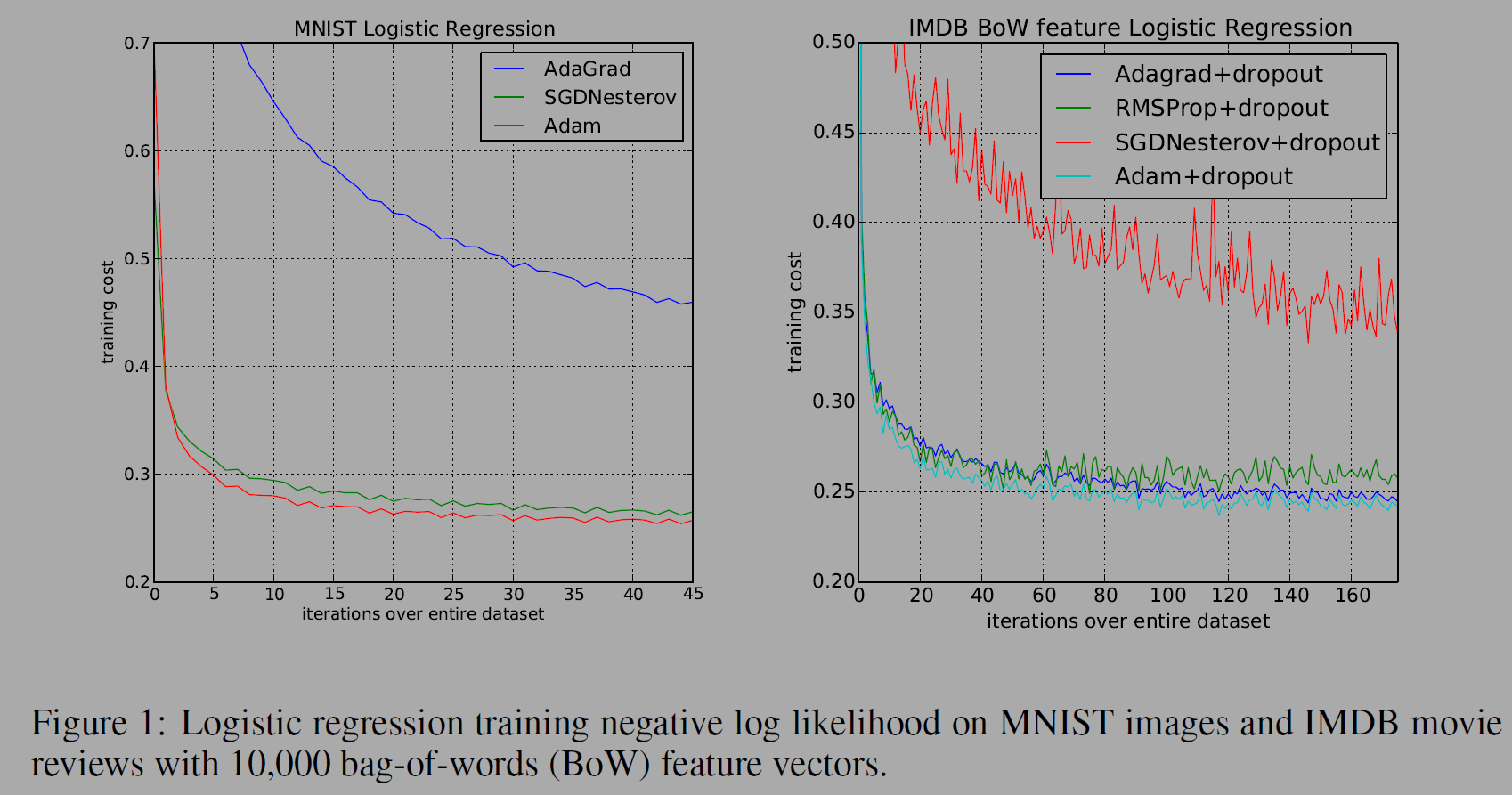
아래 그림은 뉴럴넷을 다중으로 쌓은 MNIST을 통한 비교이다.

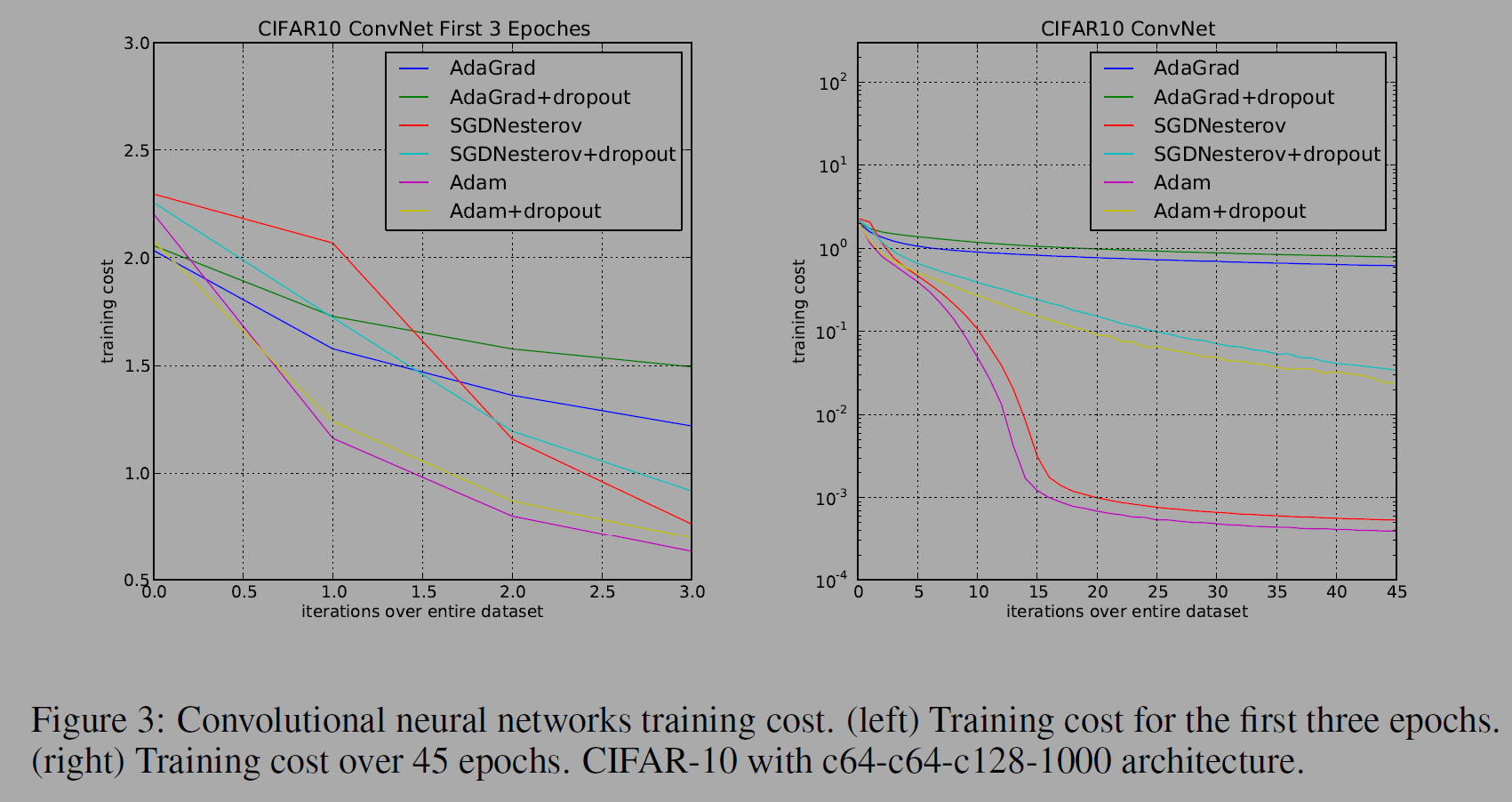
아래 그림은 CNN모델에서 옵티마이저를 비교한 실험이다.
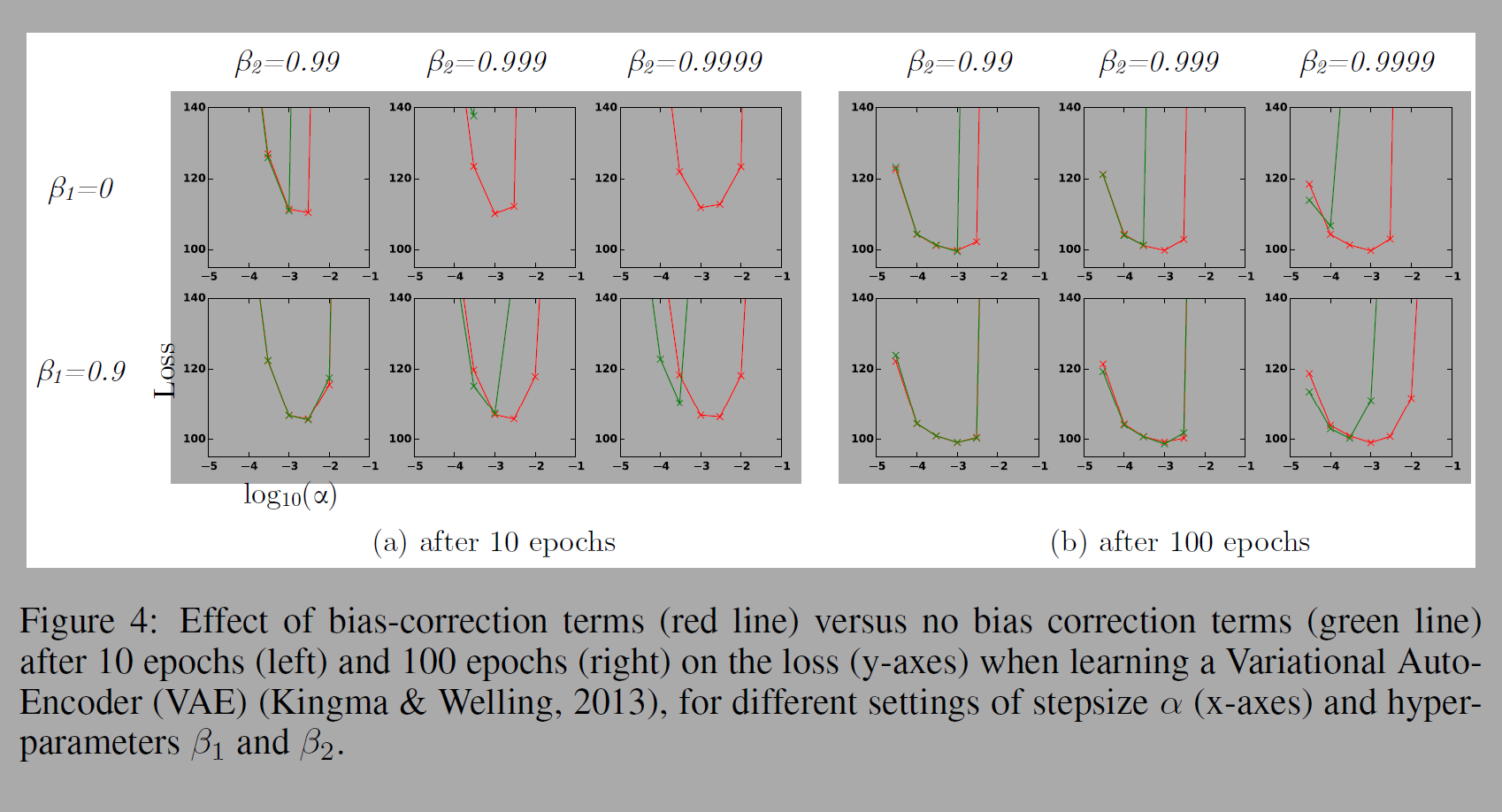
아래 실험은 bias를 교정한 것과 교정하지 않은 것을 비교한 실험이다. 하이퍼파라미터, stepsize를 변경하며 실험했다.
아래 그림은 저자들이 제안하는 새로운 방법이다.

REFERENCE
ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION
ChatGPT (최고다..)
'papers > Deep learning' 카테고리의 다른 글
| NICE: Non-linear Independent Component Estimation (0) | 2025.03.21 |
|---|---|
| Distilling the Knowledge in a Neural Network (0) | 2025.01.30 |
| XGBoost: A Scalable Tree Boosting System (3) | 2024.11.07 |
| Layer normalization (2) | 2024.09.17 |
| Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (0) | 2023.09.16 |



