논문을 읽은 지는 몇달 되었는데, 오랜 기간후에 정리를 한다.
연구 당시에는 신경망 기계번역(Neural Machine Translation)방법론에서는 원천 문장에서 선택적으로 집중하는 방식으로 모델의 성능을 개선하고 있었다. 이에 더해 attention 방법을 바탕으로 한 구조에 대해 연구가 진행되고 있는데, 본 논문에서는 모든 원천 단어를 기준으로하는 global 접근과 전체 단어중 일부를 살펴보는 local 접근 방식의 attentional 메카니즘에 대해 연구했다. 영-독 번역 테스크에서는 local 방식으로 기존방식에 비해 5.0 BLEU 테스크를 초과하여 얻었다.

기존의 NMT는 모든 단어를 읽은 뒤 문장의 끝을 나타내는 <eos> 토큰을 만난 뒤로 번역된 단어를 생성하는 방식이다. NMT는 정교한 디코더를 만들어야하는 기존 MT에 비해 쉽다. Attention 개념은 신경망에서 다른 modality를 가진 데이터를 학습하는 장점이 있는 방식인데, 기계번역에서는 2015년 Bahdanau의 연구로부터 attentional 한 방식이 주목받기 시작했다.
입력 단어의 전부를 주목하는(attend) Global 방식은 Bahdanau의 모델과 유사하고, local 방식은 2015년 Xu가 제안한 hard, soft attention 모델의 혼합버전 같다. global 모델보다는 계산량의 이점이 있고 대부분 위치에서 미분가능하여 학습이 가능하다. 저자들은 학습의 용이성, 긴 문장을 다루는 능력, alignment 품질, 번역 결과, attentional 구조의 선택이라는 관점에서 실험했다.
저자들의 연구에서는 stacking LSTM 구조를 사용했다. 목적함수는 아래와 같다.

Global, local의 차이는 전체를 대상으로하느냐, 일부를 대상으로 하느냐이다. 두 모델의 공통점은 디코딩의 t시점에 stacking LSTM 모델의 hidden state 중 제일 상단 레이어를 입력으로 사용하는 것이다. 목표는 타겟 단어 $y_t$를 예측하는데 도움이 되는 정보를 포착하는 source side context vecter를 획득하는 것이다. hidden state와 context vecter를 합쳐서(concat) 새로운 attentional hidden state를 만든다. 그리고 이를 softmax에 입력하여 새로운 weight를 얻는다.
Global attention의 모델은 아래 그림과 같다.
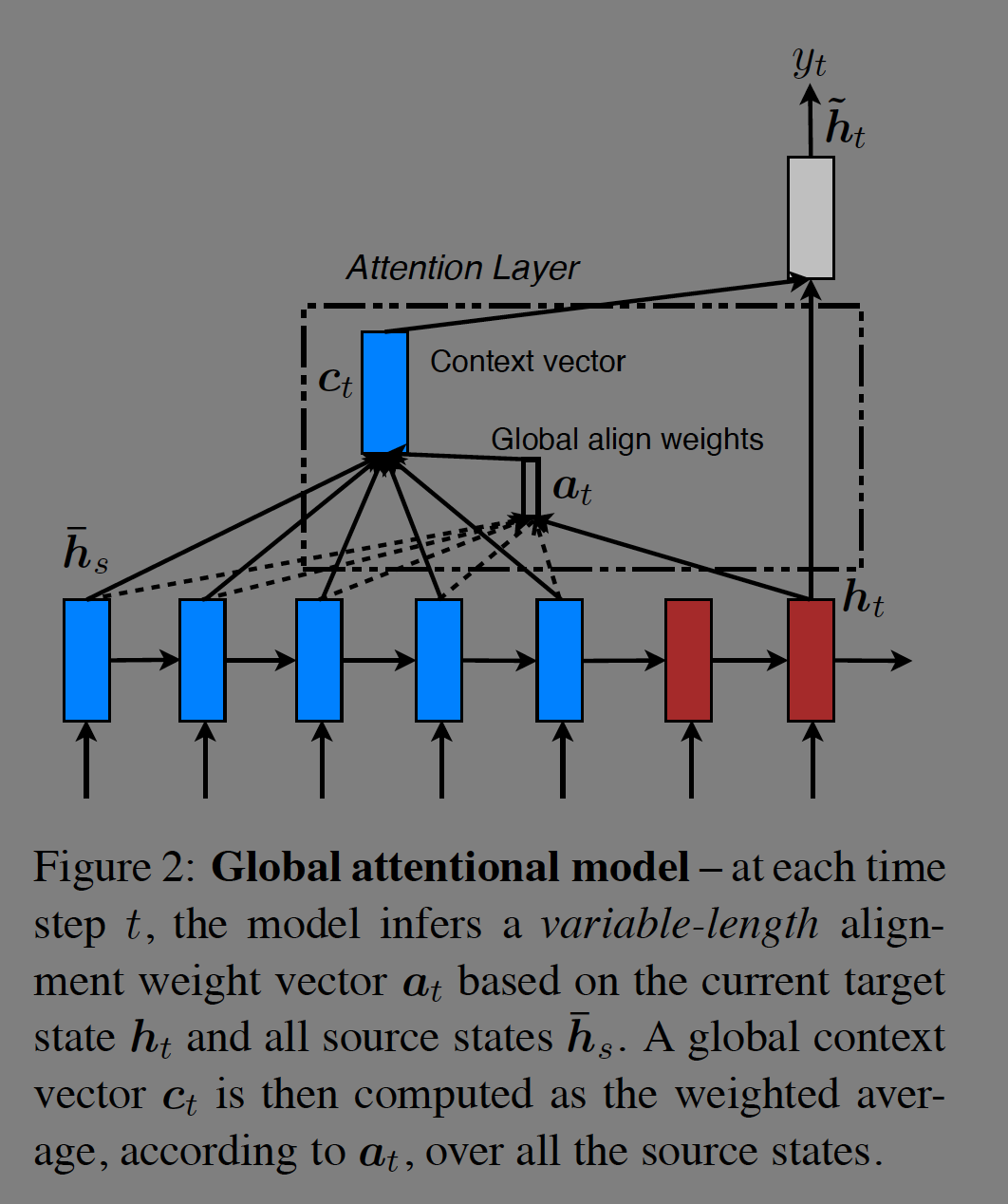
Alignment vecter $a_t$의 길이는 source side의 길이와 같다. 수식은 다음과 같다. 전체 source의 가중합과 같은 형태이다. 단점으로는 모든 단어에 관심이 있기 때문에 비용이 비싸고 문단이나 문서단위의 긴 시퀀스를 번역하는데 실용적이지 않다.

Local attention의 모델은 아래 그림과 같다. Local 모델은 미분가능한 작은 window에 집중한다. 모델은 먼저 aligned position $p_t$를 생성한다. 그리고 $c_t$는 window크기의 hidden state의 가중 평균이다.

Alignment vector는 정해진 길이로 window의 크기는 아래 두 방법에 의해 정해진다.

Global alignment를 구하는 방식에 가우시안 분포를 곱한다.

Attentional vector는 다음 타임스텝의 입력으로 이용(concat)한다.

실험결과는 WMT14 독-영 테스크에서 non attention 모델에 비해 5.0 BLEU score를 갱신했다. 2015년 SOTA 모델이었던 Jean의 모델에 비해선 1.4점 높다. WMT15 결과에 비해서는 25.9로 SOTA모델에 비해 1.0높다. 그 뒤에는 어떤 attention 구조를 사용할지에 대한 실험을 기술했다.
'papers' 카테고리의 다른 글
| ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION (3) | 2024.10.16 |
|---|---|
| Layer normalization (2) | 2024.09.17 |
| Human-level control through deep reinforcement learning (0) | 2024.02.19 |
| End-To-End Momory Networks (1) | 2023.11.17 |
| Fast R-CNN (0) | 2023.10.15 |



