이 논문은 RCNN(Region-based CNN) -> Fast R-CNN -> Faster R-CNN으로 이어지는 객체 검출(object detection)에 관한 연구를 다뤘다. 2015년 경에 연달아 해당 논문들을 게제하며 이전 논문들에서 갖고 있는 문제들을 해결했다. Fast R-CNN에서는 RCNN방법에 비해 더 나은 성능(mAP)를 보이면서 VGG16 모델을 9배 빠르게 학습하고 213배 빠르게 테스트할 수 있다. SPPnet에 비해서도 속도가 빠르고 성능이 좋다.
이 연구의 기여는 다음 그림 네가지이다.

이전 연구에서는 CNN으로 학습한 피쳐에 SVM을 분류기로 사용하여 모델의 처음부터 끝까지 학습이 되지 않는 2stage 문제가 있었고, 클래스 분류와 객체의 영역(bounding box)을 구분하는 것을 따로 계산했기 때문에 계산비효율적이다. 학습시에 5k 이미지에서 2.5GPU-days 테스트시에 이미지당 47초로 속도도 느리고 수백 기가의 저장공간이 필요했다.
그리고 매 객체 검출 시마다 CNN 네트워크를 통과시켜야 했다. SPPnet에서는 sharing computation을 통해 테스트 시에 RCNN을 최소 수십배 가속하고 피쳐 추출도 세배 정도 빠르게했지만, multi-stage 학습과 디스크 용량이 많이 필요하다는 단점을 그대로 갖고 있었다.
본 연구에서는 softmax 분류기를 만들었다. GPU를 사용하여 계산이 가능하고 multi task loss로 계산효율적인 모델을 구성되었다.
Fast RCNN 모델의 아키텍쳐는 아래 그림과 같다. 입력으로 전체 이미지를 받고 (no warp) CNN 층을 거쳐 컨볼루션 피쳐맵을 만들고 RoI 풀링을 통해 고정된 길이의 피쳐 벡터를 만든다. 그리고 피쳐 벡터를 클래스 분류, bbox 분류에 공통으로 사용한다. RoI 플링층에서는 맥스 풀링을 이용하는데, h x w 크기의 피쳐를 H x W 크기로 압축하는 역할을 한다. Sub-window를 계산하는 방식은 SPPnet의 only one pyramid level의 풀링계층과 같다고 한다.

Fast RCNN 모델은 softmax 분류기와 bbox regressor를 아래 수식으로 한번에 학습해 최적화한다.
p: probability of classes, t^u: coordination of t, u: ground truth class, v: target of ground truth bbox
고유값 표시 hyperparameter로 두 가지 태스크의 정도를 조율한다.

bounding box regression에서는 아래의 손실함수(loss)를 사용한다. RCNN과 SPPnet에서는 L1 loss가 L2 loss에 비해 아웃라이어에 덜 민감하다(robust). 실험에서는 v_i를 0 mean, 1 variance로 표준화하였다.
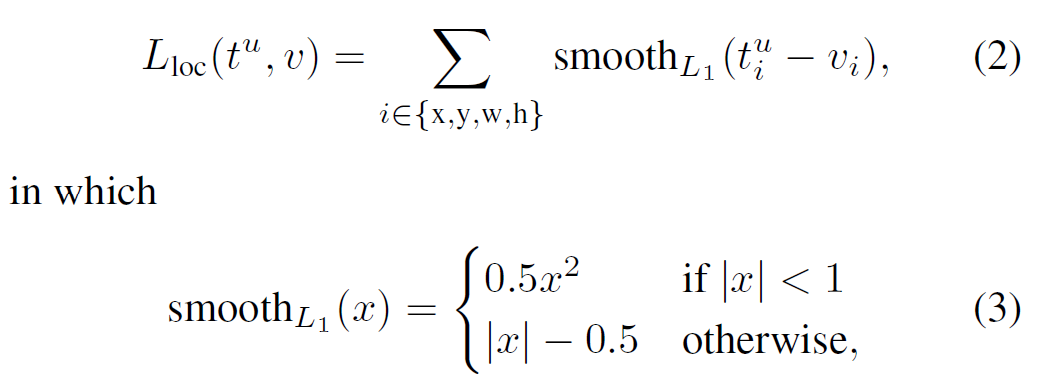
RoI 풀링 계층의 백프롭 계산은 논문의 3페이지 Back-propagation through RoI pooling layers 부분을 참조하면 된다.
객체 검출시에는 FCN을 Truncated SVD 기법을 통해 속도를 증가시켰다.
저자들이 주장하는 연구 기로는 아래 그림과 같다.

실험 셋업과 결과, 더 많은 디텍팅 프로포절에 대한 실험 결과는 원문을 참조바란다.
Reference
https://arxiv.org/abs/1504.08083



